
How do you scale LLM inference to handle thousands of concurrent users?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate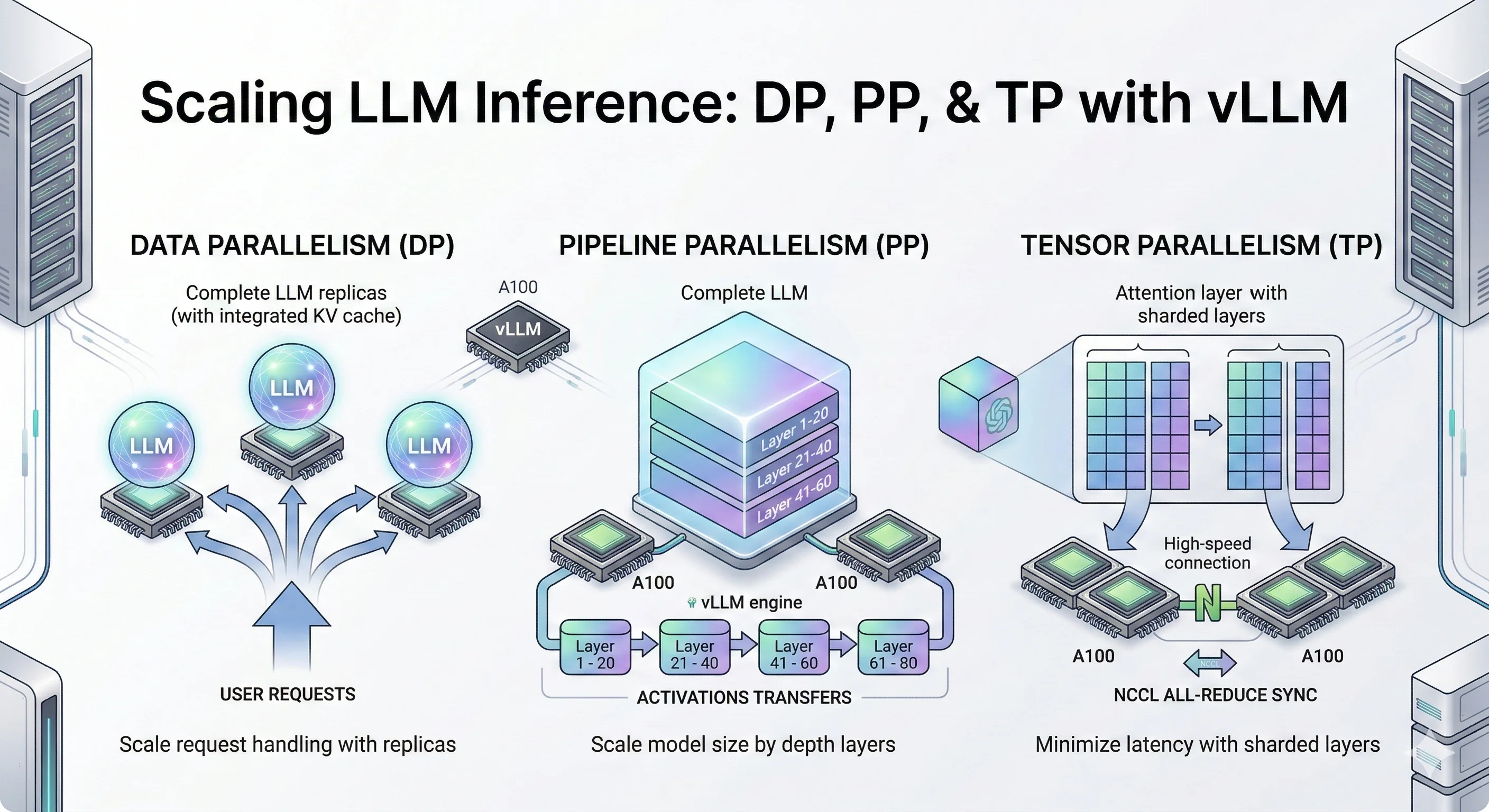
How do you scale LLM inference to handle thousands of concurrent users?
You scale LLM inference to thousands of concurrent users by maximizing throughput per GPU and then scaling horizontally with smart routing. The core moves are: run a continuous-batching inference server (vLLM, TGI, TensorRT-LLM) to pack many requests onto each GPU, add caching (semantic and prefix) to avoid redundant work, autoscale GPU replicas behind a load balancer, route traffic across replicas and models intelligently, and stream tokens so users get responses immediately.
Done well, a modest GPU fleet serves thousands of concurrent users because most of the latency users feel is hidden behind streaming and batching.
First, maximize throughput on each GPU
Scaling starts at the single-GPU level. If each GPU serves few concurrent requests, you will need an impractically large fleet. The fix is continuous (in-flight) batching, where the server interleaves many users' requests in one running batch at the token level, keeping the GPU saturated.
Engines like vLLM (with PagedAttention), TensorRT-LLM, SGLang, and TGI do this and can serve dozens to hundreds of concurrent streams per GPU depending on model and sequence length.
Efficient KV-cache management is the other half. PagedAttention eliminates memory fragmentation so more concurrent requests fit; prefix caching reuses the KV cache for shared system prompts. Together these let one GPU hold far more simultaneous conversations than naive serving.
Cut load before it reaches a GPU
The cheapest request is the one you never run. Two caching layers reduce GPU load directly:
- Semantic caching returns a stored answer when a new question is similar enough to a previous one, catching rephrased duplicates.
- Prefix caching reuses computation for shared instruction prefixes, which is common in RAG and agent workloads with fixed system prompts.
For high-traffic apps, even a moderate cache hit rate meaningfully shrinks the GPU fleet you need. Place caching in an AI gateway or the inference server so it applies uniformly.
Scale horizontally with replicas and a load balancer
Once each GPU is efficient, you scale out by running multiple replicas of the model behind a load balancer. A cluster layer like Ray Serve or Kubernetes (often with KServe) manages replicas, health checks, and rolling updates. The load balancer distributes incoming requests, and because LLM requests are long-lived streams, you want a balancer aware of replica load — least-outstanding-requests routing beats naive round-robin for token-streaming workloads.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Autoscale to follow traffic
Traffic to user-facing apps is spiky. Autoscaling adds replicas during peaks and removes them when traffic falls, so you pay for capacity you use. Scale on the right signals: queue depth or pending-requests-per-replica is a better trigger for LLM serving than raw CPU, because the GPU bottleneck shows up as a growing request queue before any host metric moves.
Configure sensible minimums to absorb sudden bursts and maximums to cap spend, and account for GPU startup time by scaling ahead of demand where possible.
Route intelligently across models and providers
Not every request needs your largest model. Model routing sends simple requests to a small, cheap model and escalates only hard ones to a large model, which multiplies effective capacity. For resilience, route across multiple replicas and even providers with automatic fallback, so a throttled or failed backend does not surface as a user error.
An AI gateway (LiteLLM, Portkey, Kong AI Gateway) centralizes this routing, fallback, rate limiting, and per-tenant quotas.
Stream tokens to hide latency
LLMs generate token by token, so total response time can be long, but users perceive the experience as fast when you stream tokens as they are produced. Streaming dramatically improves perceived performance and lets a system feel responsive to thousands of users even when each full response takes seconds.
Ensure your server, gateway, and client all support server-sent events or streaming responses end to end.
Protect the system with rate limiting and quotas
At thousands of users, a few heavy callers or a traffic spike can starve everyone else. Rate limiting and per-tenant quotas keep one user or team from monopolizing capacity, and a queue with backpressure smooths bursts instead of overloading GPUs. Combine this with graceful degradation — for example, routing overflow to a smaller model — so the system stays responsive under peak load rather than failing hard.
Putting it together
A reference architecture for thousands of concurrent users looks like: clients stream from an AI gateway that handles auth, rate limiting, caching, and routing; the gateway balances across autoscaled replicas of a continuous-batching engine like vLLM running on quantized models; a cluster layer (Ray Serve or Kubernetes) manages replicas and scaling on queue-depth signals; and monitoring (Prometheus/Grafana plus an LLM observability tool) watches latency, throughput, and queue depth so you scale before users notice.
This stack routinely serves thousands of concurrent sessions on a fleet far smaller than naive serving would require.
Frequently Asked Questions
How many concurrent users can one GPU handle? It varies widely by model size, sequence length, and GPU, but with continuous batching a single modern GPU can serve dozens to hundreds of concurrent streaming requests. Naive one-at-a-time serving handles only a handful, which is why batching is the first thing to fix.
What should I autoscale on? Use queue depth or pending requests per replica rather than CPU. The GPU bottleneck appears as a growing request queue before host metrics react, so queue-based scaling responds faster and more accurately for LLM workloads.
Does caching really help at scale? Yes. Semantic caching eliminates GPU work for repeated or rephrased questions, and prefix caching saves recomputation on shared system prompts. Even a moderate hit rate noticeably reduces the GPU fleet needed for a given traffic level.
How do I keep one user from hogging capacity? Enforce rate limits and per-tenant quotas at the gateway, add a queue with backpressure to smooth bursts, and degrade gracefully (for example, route overflow to a smaller model) so heavy users do not starve everyone else.
Why is streaming important for scale? Streaming sends tokens as they are generated, so users perceive fast responses even when full generation takes seconds. This improves perceived performance and lets the system feel responsive to many simultaneous users without raising raw throughput.
Should I route requests to different models? Often yes. Sending simple requests to a small model and escalating only hard ones to a large model multiplies effective capacity and cuts cost. An AI gateway makes this routing, plus fallback and quotas, transparent to your application.
Sources
- VLLM documentation on PagedAttention and continuous batching
- NVIDIA TensorRT-LLM and Triton documentation
- Ray Serve documentation on autoscaling and serving
- Kubernetes and KServe autoscaling documentation
- LiteLLM, Portkey, and Kong AI Gateway routing documentation
- Prometheus and Grafana monitoring documentation