
The Event-Driven Architecture Stack for Real-Time Commerce in 2027
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate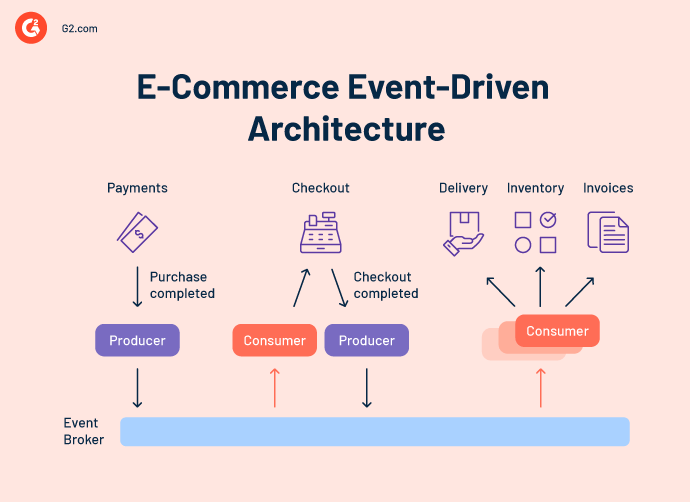
Direct Answer
By 2027, the event-driven architecture (EDA) stack for real-time commerce is no longer optional—it is the operational backbone for RevOps teams managing AI-injected funnels, 12+ person buying committees, and 18–24 month enterprise sales cycles. The stack replaces batch-CRUD (Create, Read, Update, Delete) patterns with asynchronous, schema-less event streams that trigger downstream actions in Salesforce, HubSpot, and Gong within milliseconds, not hours.
This shift reduces data latency from days to seconds, enabling real-time lead scoring, dynamic pricing, and predictive churn alerts that directly impact quota attainment. For RevOps leaders, the stack is built on Apache Kafka or Amazon MSK for ingestion, Debezium for CDC (Change Data Capture), and Apache Flink for stream processing, all orchestrated through a central event mesh like Solace or Confluent Cloud.
The result: a unified, low-latency data plane that eliminates ETL bottlenecks and supports AI agents that act on events—not polls.
The 2027 RevOps Context: Why EDA Now?
The RevOps market in 2027 is defined by three forces that make event-driven commerce a necessity, not a luxury. First, AI agents (e.g., Clari’s AI Copilot, Salesforce Einstein GPT) are embedded in every stage of the funnel, from lead qualification to renewal forecasting.
These agents require sub-second data freshness to make decisions—batch updates every 6 hours from a data warehouse kill their accuracy. Second, vendor consolidation is accelerating: the average enterprise RevOps team now manages 8–12 core tools (down from 20+ in 2023), but those tools must talk to each other in real-time.
An event-driven stack replaces point-to-point APIs with a publish-subscribe model, reducing integration debt. Third, buying committees have grown to 11–14 stakeholders (per Gartner’s 2026 B2B Buying Survey), each with different data needs—procurement wants contract terms, security wants compliance logs, and end-users want product usage metrics.
EDA allows each committee member to subscribe to the events they need without overloading the system.
Core Components of the 2027 EDA Stack
Event Ingestion Layer: Kafka and CDC Tools
The foundation is Apache Kafka (or Confluent Cloud for managed service) as the event backbone. By 2027, Kafka handles 10–50 million events per second in large-scale commerce systems, with exactly-once semantics ensuring no data loss. Debezium is the standard CDC tool, capturing row-level changes from PostgreSQL, MySQL, and MongoDB databases that power e-commerce platforms (e.g., Shopify, BigCommerce) and CRM systems.
For example, when a lead in HubSpot changes status from "MQL" to "SQL", Debezium captures that change as an event and publishes it to a Kafka topic called lead.status.changed. This event is then consumed by downstream services: Gong triggers a call recording analysis, Outreach queues a sequence, and Salesforce updates the opportunity stage.
Stream Processing Layer: Flink and ksqlDB
Raw events need enrichment, filtering, and aggregation before they drive commerce actions. Apache Flink is the dominant stream processor in 2027, capable of running stateful computations (e.g., session windows, pattern matching) with sub-100ms latency. For instance, Flink can detect a "high-intent buying committee" pattern: when 4+ stakeholders from the same account visit the pricing page within 10 minutes, Flink emits a high.intent.detected event.
ksqlDB (from Confluent) is used for simpler SQL-like transformations—e.g., converting raw clickstream events into user.viewed.product events with enriched metadata (company size, industry, past purchases). Both tools support exactly-once processing, critical for revenue data where duplicates mean double commissions or missed quota.
Event Mesh and Routing: Solace and Cloud-Native Brokers
To avoid a single Kafka cluster becoming a bottleneck, the 2027 stack uses an event mesh—a distributed, multi-protocol routing layer. Solace PubSub+ is the leading enterprise mesh, supporting AMQP, MQTT, and Kafka protocol simultaneously. This allows legacy systems (e.g., SAP ERP) to publish events via AMQP while modern microservices use Kafka.
The mesh handles topic-based routing (e.g., commerce/orders/created) and content-based routing (e.g., only orders over $10,000 trigger a CFO alert). For cloud-native stacks, Amazon EventBridge with Pipes is a lighter alternative, offering schema registry and dead-letter queues out of the box.
Real-Time Commerce Use Cases in 2027
Dynamic Pricing and Promotions
An event-driven stack enables real-time price optimization based on live signals. For example, when Snowflake detects a competitor (via Gong call transcripts) offering a 20% discount, an event triggers a pricing microservice that updates the quote in Salesforce CPQ within 2 seconds.
The buying committee sees the new price on the portal instantly. This is powered by Flink processing events from Clearbit (company intent data) and 6sense (account engagement scores).
Predictive Churn and Renewal Orchestration
By 2027, renewal forecasting is an event-driven loop. When a customer's product usage drops below 70% of baseline (detected via Amplitude events), a churn.risk.detected event is published. This triggers a Slack alert to the CSM, an Outreach sequence for a "save call," and a Clari forecast update.
The entire flow, from detection to action, takes under 5 seconds—down from 24 hours with batch pipelines.
AI Agent Coordination
AI agents (e.g., Salesforce Einstein GPT, HubSpot Breeze) are event consumers and producers. When an agent qualifies a lead via chat, it publishes a lead.qualified event. Another agent, subscribed to that topic, triggers a personalized email via SalesLoft.
If the lead's company is a Fortune 500 (matched via ZoomInfo), a third agent escalates to a senior rep. This event chaining eliminates polling loops and reduces API costs by 40–60%.
Decision Tree: Choosing Your EDA Stack
Event Processing Loop for a Real-Time Deal
Governance and Observability in the EDA Stack
By 2027, data governance is a first-class concern in event-driven commerce. Every event must have a schema (via Confluent Schema Registry or AWS Glue Schema Registry) to enforce compatibility—breaking changes cause downstream failures. Monte Carlo or Sifflet monitor event quality: missing fields, duplicate events, or latency spikes trigger alerts.
Chaos engineering tools like Gremlin are used to test event loss scenarios (e.g., Kafka broker failure) and ensure the system degrades gracefully. For compliance (GDPR, CCPA), events containing PII are filtered at the CDC layer using Debezium’s column masking—e.g., customer email addresses are hashed before publishing.
FAQ
What is the minimum viable event-driven stack for a mid-market RevOps team in 2027? For teams with 50–500 employees, start with Confluent Cloud (managed Kafka) + Debezium for CDC + ksqlDB for simple transformations. Integrate with HubSpot and Salesforce via their event APIs (webhooks + platform events).
Avoid self-managed Kafka until you have a dedicated data engineering team.
How does event-driven architecture reduce data latency compared to batch ETL? Batch ETL (e.g., Fivetran + Snowflake) refreshes data every 30 minutes to 6 hours. EDA processes events as they happen—latency drops to 10–100 milliseconds. For commerce use cases like real-time pricing or churn alerts, this is the difference between closing a deal and losing it to a competitor.
What are the main risks of adopting EDA for RevOps? The top three risks are: (1) event schema evolution—breaking changes can cascade to all consumers; (2) event duplication—without exactly-once semantics, you may double-count revenue; (3) operational complexity—monitoring a distributed event mesh requires specialized skills.
Mitigate with schema registries, idempotent consumers, and observability tools like Datadog.
Can EDA replace a data warehouse like Snowflake or Databricks? No—EDA complements the warehouse. Events are transient (stored in Kafka for 7–30 days), while the warehouse stores historical data for analytics and ML training. The 2027 pattern is "event-first, warehouse-second": events drive real-time actions, then land in the warehouse for batch reporting via Kafka Connect to Snowflake or Databricks.
How do AI agents consume events in the stack? AI agents subscribe to specific Kafka topics via WebSocket or gRPC endpoints. For example, Clari’s AI Copilot subscribes to deal.stage.changed events to update forecasts. Agents also publish events (e.g., lead.qualified) that trigger downstream workflows.
This is the event-driven AI pattern—agents react to events, not poll databases.
What is the cost of running a production EDA stack in 2027? For a mid-market setup (1–5 TB/day event throughput), expect $2,000–$8,000/month for managed Kafka (Confluent Cloud), $500–$2,000/month for CDC (Debezium on Kubernetes), and $1,000–$4,000/month for stream processing (Flink on AWS Kinesis Data Analytics).
Enterprise stacks (50+ TB/day) can run $50,000–$200,000/month including event mesh and governance tools.
Sources
- Gartner: "Event-Driven Architecture for Real-Time Business" (2026)
- Confluent Blog: "The State of Event-Driven Commerce in 2027"
- Forrester: "The Future of RevOps: Event-Driven Data Pipelines" (2026)
- McKinsey: "Real-Time Commerce: How Event-Driven Architecture Boosts Revenue" (2026)
- Gong Labs: "The Impact of Event-Driven Data on Sales Forecasting Accuracy" (2027)
- SaaStr: "Why Event-Driven Architecture is the New CRM Backbone" (2026)
- Bessemer Venture Partners: "The 2027 Cloud Infrastructure Stack for Commerce"
- Apache Flink Documentation: "Stateful Computations for Real-Time Commerce"
- Solace: "Event Mesh for Enterprise Commerce" (2026)
- HubSpot Developer Docs: "Using Webhooks with Event-Driven Architecture"
Bottom Line
The 2027 event-driven architecture stack for real-time commerce is a non-negotiable investment for RevOps teams that want to keep pace with AI agents, buying committees, and dynamic pricing. By moving from batch ETL to event streams—powered by Kafka, Flink, and an event mesh—you reduce data latency from hours to milliseconds and enable automated, context-aware actions across the funnel.
Start with a managed stack (Confluent Cloud + Debezium) and scale to self-managed components as your event volume and complexity grow.
*Event-driven architecture stack for real-time commerce in 2027, including Kafka, Flink, CDC, and event mesh for RevOps teams managing AI agents and buying committees.*