
What infrastructure do you need to run AI agents in production?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate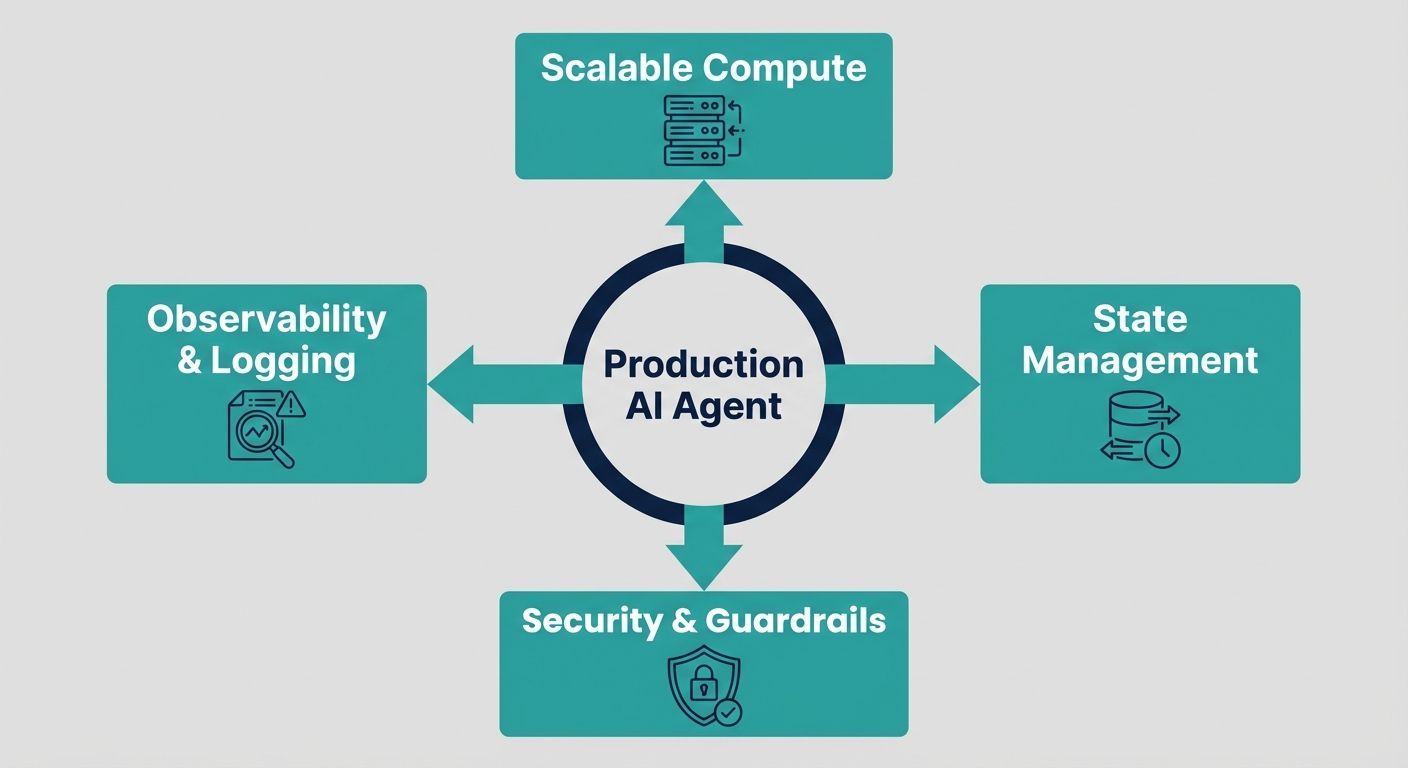
What infrastructure do you need to run AI agents in production?
Direct Answer
Running AI agents in production requires far more than an LLM API call. You need an orchestration layer to manage multi-step reasoning and tool use, reliable LLM serving (hosted APIs or self-hosted inference), a memory and state layer (short-term conversation state plus long-term vector memory), a secure tool and action layer (often a sandbox for code execution and least-privilege access to APIs and data), guardrails for safety and prompt-injection defense, deep observability and tracing to debug non-deterministic behavior, and evaluation plus cost and rate-limit controls to keep agents reliable and affordable.
Agents are long-running, stateful, and capable of taking real actions, so the infrastructure looks like a distributed system with an LLM at its core — not a stateless web service.
Why agents need more infrastructure than a chatbot
A simple chatbot takes a message and returns text. An agent plans, calls tools, observes results, and loops — sometimes for many steps — to accomplish a goal. That loop introduces hard infrastructure requirements a chatbot never had: each step is non-deterministic, steps can fail or hang, the agent holds state across the loop, it can take actions with real-world consequences, and a single user request can fan out into dozens of model and tool calls.
Production agent infrastructure exists to make this loop reliable, observable, secure, and affordable.
1. Orchestration and agent framework
The orchestration layer runs the agent loop: it manages the plan, decides when to call which tool, feeds results back to the model, and enforces stopping conditions. In 2027 the common choices are LangGraph (graph-based, stateful agent workflows), LlamaIndex (retrieval-centric agents), CrewAI and AutoGen (multi-agent collaboration), and provider-native agent SDKs.
For production you want an orchestrator that supports durable, resumable execution — so a long-running agent can survive a crash and resume — which is why some teams put a durable workflow engine like Temporal underneath the agent loop.
2. LLM serving and routing
Every reasoning step is an inference call, so you need reliable model access. That means either hosted foundation-model APIs (OpenAI, Anthropic, Google, and others) or self-hosted inference (vLLM, TGI, Triton) for control and cost. In front of these, an AI gateway / LLM router (LiteLLM, Portkey, or similar) gives you a single endpoint with retries, fallbacks across providers, rate-limit handling, caching, and centralized logging.
Agents make bursty, high-volume call patterns, so gateway-level retries, timeouts, and provider failover are not optional — a single hung call can stall an entire agent run.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
3. Memory and state
Agents are stateful in two senses. Short-term state is the working context of the current run — the plan, intermediate results, and conversation so far — which must be persisted so a run can resume. Long-term memory lets agents recall facts across sessions, typically stored in a vector database (Pinecone, Qdrant, Weaviate, pgvector) for semantic recall, plus a regular database for structured state.
Frameworks increasingly ship memory abstractions, and dedicated memory layers (such as Mem0) have emerged to manage what an agent remembers and forgets.
4. Tool and action layer (with a sandbox)
Agents are powerful because they *act* — calling APIs, querying databases, running code. This is also the most dangerous part of the stack. Production agents that execute generated code need a secure sandbox (E2B, Modal, gVisor/Firecracker-isolated containers) so code runs in an isolated, ephemeral environment with no access to your wider systems.
Tool access should follow least privilege: scoped credentials, allow-lists of permitted actions, and human approval gates for high-impact operations. The Model Context Protocol (MCP) has become a common standard for exposing tools and data to agents in a structured, governable way.
5. Guardrails and security
Because agents take actions on untrusted input — and often on content retrieved from the web or documents — prompt injection is a first-order threat: a malicious instruction hidden in a document can hijack the agent. The defenses are infrastructural: input/output guardrails (NeMo Guardrails, Guardrails AI, Lakera), treating all retrieved content as untrusted, constraining what tools the agent can call, and never letting raw model output trigger a sensitive action without validation.
Add PII filtering and policy enforcement at a central layer so every agent inherits the same controls.
6. Observability and tracing
Agents are non-deterministic and multi-step, which makes them genuinely hard to debug — you need to see *every* model call, tool call, input, and output in a run. Tracing platforms built for LLMs — LangSmith, Langfuse, Arize Phoenix, Helicone — capture the full execution trace of an agent run, so when an agent goes off the rails you can replay exactly what it saw and decided.
This visibility is the single most important operational tool for production agents; without it, you are debugging blind.
7. Evaluation, cost control, and rate limiting
Finally, you need to know whether agents are *working* and what they *cost*. Evaluation (offline test suites plus online LLM-as-judge and human review) measures whether agents complete tasks correctly and safely as you change prompts and models. Cost controls — token budgets per run, step limits to prevent infinite loops, semantic caching, and model routing (cheap models for easy steps) — keep a runaway agent from generating a runaway bill.
Rate limiting and concurrency controls protect both your providers' quotas and downstream systems the agent touches.
Putting it together
A production agent stack looks like a distributed system: an orchestrator running a durable, resumable loop; an AI gateway routing to hosted or self-hosted models with retries and fallbacks; a vector store and database for memory and state; a sandboxed, least-privilege tool layer (often via MCP) with approval gates for risky actions; guardrails screening inputs and outputs; a tracing platform recording every step; and evaluation plus cost/rate controls wrapping it all.
You can assemble this from open-source pieces or adopt a managed agent platform that bundles many of them — but the seven capabilities above are the non-negotiable parts of running agents reliably.
Frequently Asked Questions
Can't I just call an LLM API in a loop? You can prototype that way, but it breaks in production. Without durable state you lose progress on crashes; without observability you can't debug failures; without sandboxing and least privilege a hijacked agent can do real damage; without step limits and budgets a loop can run away on cost.
The infrastructure exists precisely to make the naive loop safe and reliable.
What is the biggest security risk for production agents? Prompt injection combined with tool access. Because agents act on untrusted input — web pages, documents, user messages — a hidden instruction can redirect the agent to misuse its tools. Defend with sandboxing, least-privilege scoped credentials, allow-listed actions, human approval for high-impact steps, and never letting raw model output trigger sensitive actions unvalidated.
Do I need a vector database for agents? You need one if your agents require long-term memory or retrieval over a knowledge base — which most production agents do. Short-term run state can live in a regular database, but semantic recall of past interactions or documents is what vector stores (Pinecone, Qdrant, Weaviate, pgvector) provide.
Some agents with no memory needs can skip it.
How do I keep agent costs under control? Set hard step limits to prevent infinite loops, cap token budgets per run, route easy steps to cheaper models and reserve frontier models for hard reasoning, cache repeated work (including semantic caching), and monitor cost per run in your tracing platform.
A runaway agent with no limits is the classic way to generate a surprise bill.
What does observability give me that normal logging doesn't? LLM-aware tracing reconstructs the full causal chain of an agent run — every prompt, model response, tool input, and tool output, nested by step — so you can replay exactly what the agent saw and why it decided what it did.
Plain logs scatter this across systems; agent tracing (LangSmith, Langfuse, Phoenix) assembles it into a debuggable timeline.
What is MCP and why does it matter for agents? The Model Context Protocol is an open standard for exposing tools, data, and context to LLM agents in a consistent, structured way. It matters because it standardizes how agents connect to external systems, making tools reusable across frameworks and easier to govern centrally rather than wiring bespoke integrations into every agent.
Sources
- LangGraph documentation — https://langchain-ai.github.io/langgraph/
- Anthropic — Building effective agents — https://www.anthropic.com/research/building-effective-agents
- Model Context Protocol documentation — https://modelcontextprotocol.io/
- LangSmith observability documentation — https://docs.smith.langchain.com/
- E2B secure code sandbox documentation — https://e2b.dev/docs
- Temporal durable execution documentation — https://docs.temporal.io/
- LiteLLM gateway documentation — https://docs.litellm.ai/