
What attribution model works for a multi-touch enterprise sales motion?

For enterprise multi-touch motions, run three attribution models in parallel rather than picking one: first-touch for lead-gen credit, last-touch for sales-motion credit, and W-shaped multi-touch (30/30/30/10) for pipeline diagnosis. Single-touch attribution lies systematically when the median enterprise deal sees 5-9 touches over 6+ months and involves 6.8 buying-group members on average per Gartner's B2B Buying research (https://www.gartner.com/en/sales/insights/b2b-buying-journey). The right answer isn't a model; it's a model triangulation discipline -- AND a willingness to test it adversarially with incrementality holdouts.
Why single-touch fails (the real mechanics)

A $500K deal touches marketing 7 times (content -> webinar -> whitepaper -> 3 nurture emails -> retargeting), then sales 3 times (cold call -> demo -> proposal). Last-touch credits the proposal and tells marketing they did nothing. First-touch credits the blog post and tells sales they did nothing.
Both are fiction. Forrester's B2B buyer research (https://www.forrester.com/blogs/category/b2b-buying/) finds the average enterprise buying group spans 6 to 10 stakeholders and produces roughly 27 distinct buying-group interactions across the cycle -- meaning even "first touch" is a compression of 6+ first touches per account.
Salesforce's State of Sales 6th Edition (https://www.salesforce.com/resources/research-reports/state-of-sales/) found 32% of revenue leaders explicitly distrust their attribution data, and 67% of reps say enterprise wins require coordinated multi-channel outreach -- not a single decisive touch.
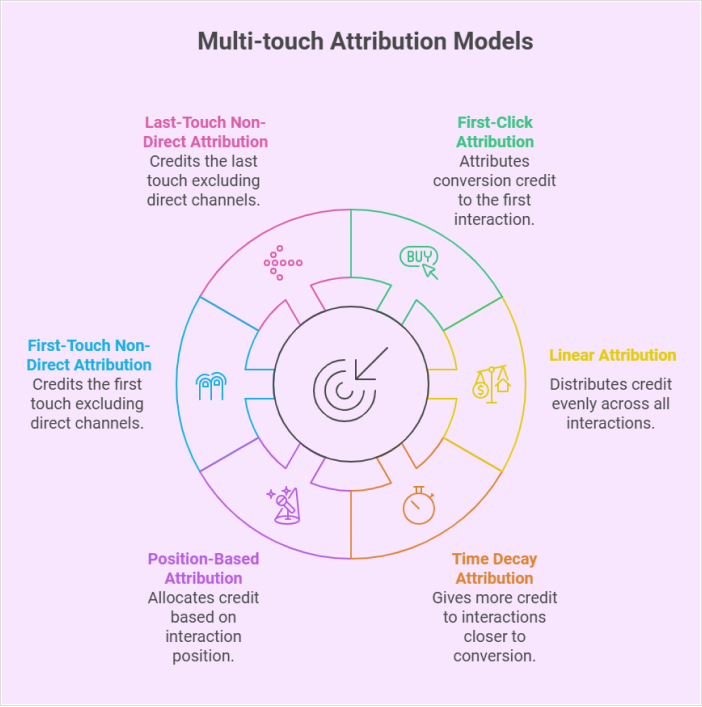
The three models, with real formulas
1. First-touch (lead-gen accountability)
- Question answered: Which channel created the account record?
- Use for: Marketing channel budget allocation (paid, content, events, partner)
- Formula: 100% credit -> first Campaign Member record on the Account in CRM
- Trap: First-touch is dominated by cheap top-of-funnel. If 60% of first touches are paid social, that's spend volume, not skill
- Reference: HubSpot's multi-touch attribution docs (https://knowledge.hubspot.com/reports/use-multi-touch-revenue-attribution-reports) describe default channel mapping and weighting
2. Last-touch (closing-motion accountability)
- Question answered: Which sales motion (inbound AE, outbound SDR->AE, expansion CSM, channel) closed it?
- Use for: Sales headcount allocation; if expansion closes 40% of revenue, fund expansion
- Formula: 100% credit -> last Activity tied to Opportunity at Closed-Won timestamp
- Trap: Sales claims credit for warm leads marketing built; resolve via the multi-touch view. Forrester finds 70% of B2B buyers engage 3+ pieces of content before talking to sales -- last-touch hides all of it.
3. Multi-touch (journey truth)
- Question answered: What is the actual customer journey?
- Use for: Identifying high-leverage middle touches that neither pure first nor pure last reveals
- Common weights (verified):
- U-shaped: 40% first / 40% last / 20% split across middle touches
- W-shaped: 30% first / 30% lead-conversion / 30% opportunity-creation / 10% middle (Bizible/Adobe Marketo benchmark default)
- Time-decay: exponential half-life of 7 days back from Closed-Won (HubSpot/Marketo default)
- Tools: Salesforce Einstein Attribution, HubSpot Marketing Hub Enterprise, Bizible/Adobe, Dreamdata, custom dbt+Looker model
Realistic example ($20M ARR, 60% enterprise mix)
| Deal | First Touch | Mid Touches | Last Touch | W-Shape Credit |
|---|---|---|---|---|
| $300K | Content (30%) | Webinar conv (30%), Demo opp-create (30%) | Proposal | Content $90K, Webinar $90K, Demo $90K, Proposal $30K |
| $100K | Paid Ad (30%) | SDR call lead-conv (30%), Whitepaper opp-create (30%) | Negotiation | Paid $30K, SDR $30K, WP $30K, Neg $10K |
Operational implementation (90-day rollout)
- Days 1-30: Force every touch into Salesforce Activity + Campaign Member (no Activity = didn't happen). Without Activity hygiene, every model is garbage-in. Target >=95% Activity-on-Opportunity coverage before any model output is shared.
- Days 31-60: Stand up three dashboards -- one per model -- using the same Opportunity universe (same date filter, same stage cutoff).
- Days 61-90: Quarterly review with CFO + RevOps as neutral arbiter. If first/last/multi tell different stories, the gap IS the insight.
- Year 1: Lock the model. Don't re-weight mid-year; you'll be optimizing to noise.
Bear Case (adversarial -- the case against attribution as you've been sold it)
Attribution is largely theater for boards. The honest critique:
- None of these models prove causation. First/last/multi-touch are correlation dressed up as math. The only causal evidence comes from randomized incrementality tests -- geo holdouts (Google Geo Experiments, Meta Conversion Lift, Nielsen MMM) -- and most CMOs refuse to run them because they expose dead spend. Salesforce's 32% distrust rate is the polite version of this.
- The deal-flipping touch is usually invisible. In a 6-month, 6.8-stakeholder enterprise cycle, the marginal interaction that flipped the deal is almost never the first or last in your CRM. It's a back-channel reference call, a Slack DM between champion and CFO, a hallway conversation at a customer event. If your CRM doesn't see it, no model can credit it.
- Multi-touch weights (40/40/20, W-shape 30/30/30/10) are arbitrary. Vendors picked them because they look balanced and pass executive smell-tests, not because randomized data justified them. Try re-running the same opportunities with three different weight schemes -- the channel rankings will move.
- Vendor-defined attribution is captured. When the platform that runs your campaigns also reports your campaign ROI, ask whether you trust the umpire to call balls and strikes against itself. Independent measurement (Bizible bought by Adobe; Dreamdata; data-warehouse-native models in dbt + Looker) reduces but does not eliminate this conflict.
Counter-prescription: If you must pick one model and you sell to enterprise, pick W-shaped multi-touch AND pair it with quarterly geo-level or audience-level incrementality holdouts on the top two paid channels. Anyone selling "unified attribution" without holdouts is selling vibes, not measurement.
Action: Pick W-shaped as primary. Implement for 12 months. Don't change weights. Pair with quarterly incrementality holdouts. Compare to last-touch monthly to detect drift.
Related Pulse knowledge
- /knowledge/q05 -- pipeline coverage math (3x rule and how attribution feeds it)
- /knowledge/q33 -- RevOps reporting cadence (where the three dashboards live)
- /knowledge/q47 -- sales-marketing SLA design (the SLA referee for first-vs-last disputes)
- /knowledge/q88 -- enterprise deal velocity (why touch-count and stage-time matter together)
- /knowledge/q103 -- forecast accuracy (downstream of clean attribution; without one the other lies)
TAGS: attribution-model, multi-touch, enterprise-sales, pipeline-analysis, marketing-sales-alignment, w-shaped, incrementality
Recently Added — Related
FAQ
Why run three attribution models in parallel instead of picking one? For enterprise multi-touch motions you run first-touch for lead-gen credit, last-touch for sales-motion credit, and W-shaped multi-touch (30/30/30/10) for pipeline diagnosis. The median enterprise deal sees 5-9 touches over 6+ months and involves 6.8 buying-group members on average per Gartner.
Single-touch attribution lies systematically because last-touch credits the proposal and tells marketing it did nothing, while first-touch credits the blog post and tells sales it did nothing.
What does the W-shaped model weight, and where does it come from? W-shaped assigns 30% to first touch, 30% to lead-conversion, 30% to opportunity-creation, and 10% to middle touches — the Bizible/Adobe Marketo benchmark default. U-shaped weights 40% first / 40% last / 20% middle, and time-decay uses an exponential 7-day half-life back from Closed-Won.
In the worked $300K example, content, webinar, and demo each get $90K while the proposal gets $30K.
What does the Salesforce State of Sales data say about attribution trust? The 6th Edition found that 32% of revenue leaders explicitly distrust their attribution data, and 67% of reps say enterprise wins require coordinated multi-channel outreach rather than a single decisive touch.
Forrester's research adds that 70% of B2B buyers engage 3+ pieces of content before talking to sales — all of which last-touch hides. The 32% distrust rate is described as the polite version of the deeper critique that none of the models prove causation.
What is the 90-day rollout sequence? Days 1-30, force every touch into Salesforce Activity and Campaign Member and target ≥95% Activity-on-Opportunity coverage before sharing any model output. Days 31-60, stand up three dashboards (one per model) on the same Opportunity universe.
Days 61-90, run a quarterly review with CFO and RevOps as neutral arbiter — where first/last/multi disagree, the gap is the insight. Then lock the model for Year 1 and do not re-weight mid-year.
What is the bear case against attribution as it is sold? None of the models prove causation — they are correlation dressed up as math, and the only causal evidence comes from randomized incrementality tests like geo holdouts (Google Geo Experiments, Meta Conversion Lift, Nielsen MMM), which most CMOs refuse to run.
The deal-flipping touch is usually invisible (a back-channel reference call or a Slack DM the CRM never sees), the multi-touch weights are arbitrary, and vendor-defined attribution is captured by the platform running the campaigns.