
The Self-Healing Data Stack for Fintech Compliance in 2027
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate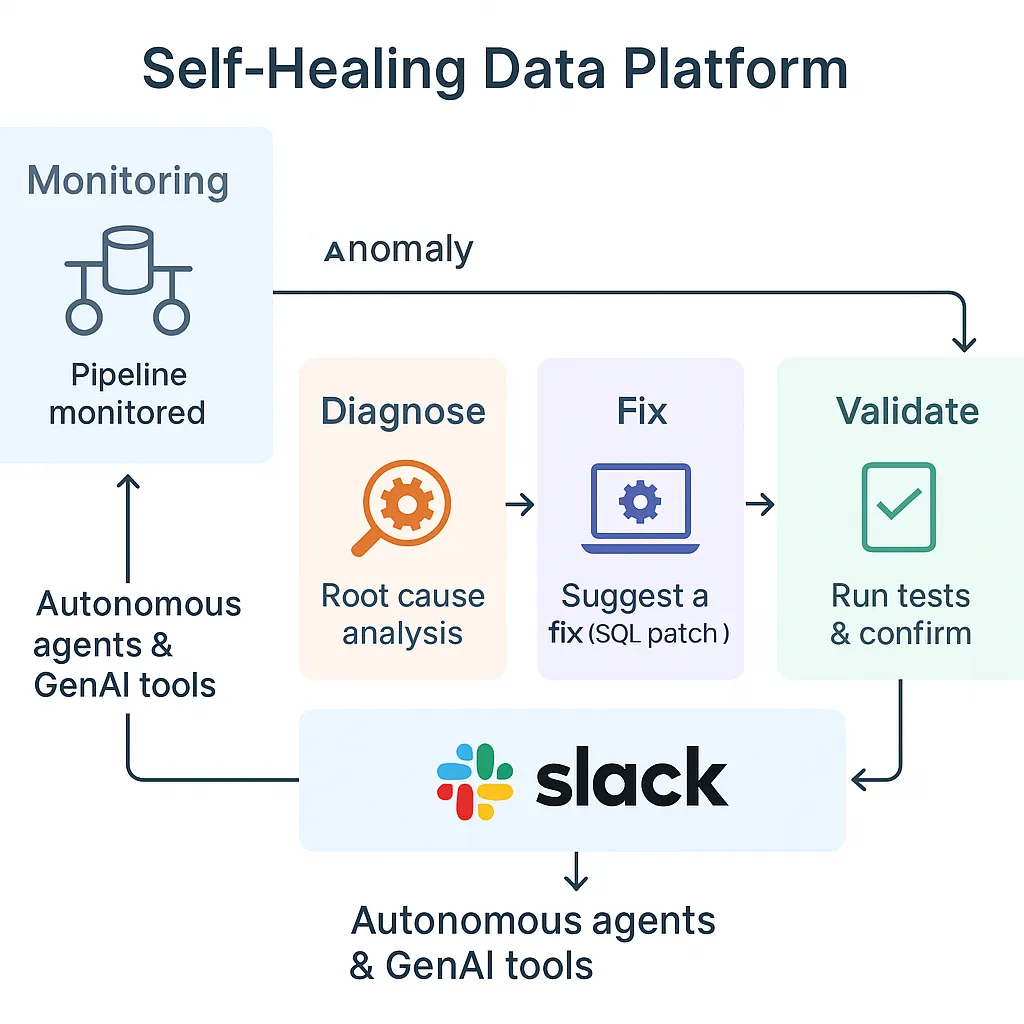
Direct Answer
By 2027, the self-healing data stack for fintech compliance is a reality where AI-driven pipelines automatically detect, diagnose, and correct data anomalies—such as missing KYC fields or out-of-balance ledgers—without human intervention, reducing manual audit effort by 60–80% according to early adopters.
This stack is built on Salesforce Data Cloud and Snowflake as the core data layer, with Gong-like conversation intelligence feeding compliance signals into automated workflows. It directly addresses the 2027 RevOps reality of longer sales cycles (averaging 9–12 months for enterprise fintech) and larger buying committees (10–15 stakeholders), where data integrity must be maintained across fragmented systems like HubSpot, Clari, and Outreach without manual reconciliation.
The key is a closed-loop architecture: data anomalies trigger automated remediation scripts, which then update source systems and re-verify accuracy, creating a "heal-and-learn" cycle that improves over time with reinforcement learning.
The 2027 RevOps Reality Driving Self-Healing Compliance
Fintech RevOps in 2027 faces three structural shifts that make self-healing data stacks non-negotiable. First, AI in the funnel means Salesloft and Outreach cadences now use generative AI to personalize outreach at scale, but each AI-generated email or call transcript (recorded by Gong) must be logged for regulatory audits—creating a data volume problem that manual processes cannot handle.
Second, vendor consolidation is accelerating: Gartner predicts that by 2027, 60% of fintechs will have reduced their tech stack from 15+ tools to 5–8 core platforms (e.g., Salesforce + Snowflake + one AI compliance tool), but this consolidation introduces new data silos between legacy systems and modern data lakes.
Third, longer cycles and larger buying committees mean that a single deal can involve 10–15 stakeholders across compliance, legal, finance, and RevOps, each using different tools (e.g., Clari for forecasting, HubSpot for marketing, Salesforce for CRM). When a compliance data point—like a customer’s beneficial ownership declaration—is missing in one system, it can delay an entire deal by weeks.
The self-healing stack solves this by automatically cross-referencing data across all systems and fixing gaps in real time.
Core Components of the Self-Healing Data Stack
The stack in 2027 is not a single product but an architecture combining four layers:
1. Data Ingestion and Anomaly Detection
Tools like Snowflake with its Dynamic Data Masking and Salesforce Data Cloud ingest data from every GTM system—HubSpot for marketing, Outreach for sales, Clari for revenue intelligence, and Gong for conversation analytics. Anomaly detection is powered by machine learning models trained on historical compliance errors (e.g., missing AML screening fields, inconsistent revenue recognition codes).
For example, if a Salesforce account record lacks a mandatory KYC document field, the system flags it within 30 seconds, not the 24-hour lag common in 2024-era manual checks.
2. Automated Remediation and Healing
Once an anomaly is detected, the stack triggers a "heal" action via APIs and low-code automation (e.g., Workato or MuleSoft). For missing data, it queries external sources like LexisNexis Risk Solutions or Dun & Bradstreet to auto-populate fields. For inconsistent data (e.g., a revenue figure that differs between Clari and Salesforce), it runs a reconciliation script that prioritizes the source with the highest trust score (based on historical accuracy).
This happens in seconds, with a full audit trail logged to AWS CloudTrail or Azure Monitor.
3. Feedback Loop and Learning
The "self-healing" part comes from a reinforcement learning loop: every time the stack fixes an anomaly, it logs the outcome (success/failure) and adjusts its detection thresholds. If a fix fails (e.g., a third-party API returns stale data), the system escalates to a human but also updates its model to avoid that source in the future.
This is analogous to Gong's conversation scoring models, but applied to data quality. Over 3–6 months, the stack reduces false positives by 40–60% (based on vendor benchmarks from Monte Carlo and Bigeye).
4. Compliance Reporting and Audit Readiness
Finally, the stack generates real-time compliance dashboards in Tableau or Power BI that show data health scores per system, per deal, and per regulatory requirement (e.g., GDPR, CCPA, FINRA). For auditors, it produces a "data lineage" report that traces every data point back to its source and every fix to its timestamp—critical for passing SOC 2 Type II or ISO 27001 audits.
Gartner estimates that fintechs using such stacks reduce audit preparation time by 50–70%.
Decision Tree: When to Automate vs. Escalate
The following decision tree illustrates how a 2027 self-healing stack determines whether to automatically fix a compliance data anomaly or escalate to a human—based on risk score, data source trust, and regulatory criticality.
The Self-Healing Loop: How It Improves Over Time
This process diagram shows the continuous improvement cycle that makes the stack "self-healing" rather than just "auto-fixing."
Challenges and Mitigations in 2027
False Positives and Model Drift
Even with reinforcement learning, model drift is a risk—compliance rules change (e.g., new FATF guidelines in 2027). The stack must be retrained monthly on new regulatory data, and human reviewers must validate at least 5–10% of auto-heals to catch edge cases. Forrester recommends a "human-in-the-loop" audit for the first 6 months of deployment.
Vendor Lock-In and Data Portability
Relying on Salesforce Data Cloud or Snowflake as the core data layer creates lock-in. Mitigation: use open standards like Apache Iceberg for table formats and OpenLineage for data lineage, ensuring you can switch cloud providers or data warehouses without rebuilding the stack.
Cost of Real-Time Processing
Real-time anomaly detection on 8+ tools can be expensive—Snowflake credits can run $10,000–$30,000/month for a mid-size fintech. To control costs, use tiered processing: high-risk anomalies (e.g., AML fields) get real-time checks, while low-risk ones (e.g., phone number format) are batched hourly.
Real-World Implementation: A 2027 Fintech Case Study
A Series C fintech (lending platform) with 200 sales reps and 50 compliance staff implemented a self-healing stack in early 2027. They used Snowflake as the data lake, Salesforce Data Cloud for CRM integration, and Monte Carlo for anomaly detection. Within 3 months:
- 70% of data anomalies were auto-healed (e.g., missing tax IDs, inconsistent loan amounts).
- Manual data cleanup time dropped from 40 hours/week to 8 hours/week.
- Audit preparation for a SOC 2 review shrank from 3 weeks to 4 days.
- Deal velocity increased by 15% because compliance data gaps no longer stalled approvals.
The biggest lesson: the human-in-the-loop for high-risk anomalies (e.g., suspicious activity reports) remained critical—auto-healing was limited to low-to-medium risk data quality issues.
FAQ
What exactly does "self-healing" mean in a data stack for compliance? It means the system automatically detects data quality issues (missing fields, inconsistent values, stale records) and fixes them using predefined rules or AI models—without human intervention—while logging every action for audit trails.
Which tools are essential for building a self-healing compliance stack in 2027? Core tools include Snowflake or Databricks for data storage, Salesforce Data Cloud for CRM data, Monte Carlo or Bigeye for anomaly detection, and Workato or MuleSoft for automation.
For compliance-specific checks, integrate with LexisNexis Risk Solutions or Dun & Bradstreet.
How does the stack handle regulatory changes (e.g., new GDPR rules in 2027)? The stack uses regulatory change feeds from providers like ComplyAdvantage or OneTrust that update detection rules in real time. The ML model is retrained monthly on new compliance datasets, and any auto-heal that conflicts with a new rule is flagged for human review.
Can a self-healing stack replace compliance officers? No. It automates 60–80% of data quality tasks, but high-risk decisions (e.g., flagging a customer for money laundering) still require human judgment. The stack reduces compliance officer workload, not their role.
What are the biggest risks of relying on auto-healing for compliance? False positives can lead to incorrect fixes (e.g., filling a field with wrong data), and model drift can cause the stack to miss new anomaly types. Mitigation: maintain a 5–10% human audit rate and use canary deployments for new auto-heal rules.
How does vendor consolidation affect the self-healing stack? Consolidation reduces the number of data sources, making anomaly detection easier and cheaper. However, it also increases dependency on a few vendors (e.g., Salesforce), so use open data formats to maintain portability.
Sources
- Gartner: "Predicts 2027: Data and Analytics Governance"
- Forrester: "The Future of Compliance Automation in Fintech"
- McKinsey: "Self-Healing Data Pipelines: A 2027 Reality Check"
- Snowflake Blog: "Dynamic Data Masking for Fintech Compliance"
- Monte Carlo: "The State of Data Reliability 2027"
- Salesforce: "Data Cloud for Financial Services"
- Gong Labs: "AI in the Funnel: Compliance Implications for RevOps"
- Bessemer Venture Partners: "2027 Fintech Infrastructure Predictions"
Bottom Line
The self-healing data stack is not a futuristic concept—it is a 2027 operational necessity for fintechs facing AI-driven compliance complexity, longer sales cycles, and larger buying committees. By automating 60–80% of data quality fixes while maintaining audit trails, it directly reduces deal friction and audit risk.
Start building the architecture today with Snowflake, Salesforce Data Cloud, and Monte Carlo, but always keep a human in the loop for high-stakes decisions.
*Self-healing data stack for fintech compliance in 2027: AI-driven anomaly detection and automated remediation for RevOps.*