 Pulse Reviews and Analysis
Pulse Reviews and Analysis
What is an MLOps platform and what problems does it solve?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate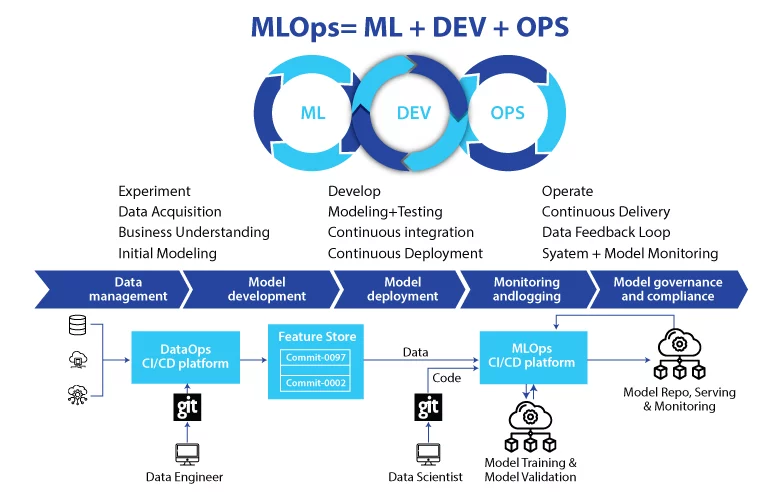
What is an MLOps platform and what problems does it solve?
An MLOps platform is the system that operationalizes machine learning — it manages the full lifecycle of a model from experimentation to production and beyond. Concretely, it provides experiment tracking, data and model versioning, pipeline orchestration for training, a model registry for governed deployments, serving infrastructure, and monitoring once models are live.
It solves the core problems that break ML in production: results no one can reproduce, no record of which model is deployed, brittle handoffs from data scientists to engineers, and silent model decay as real-world data drifts. In short, an MLOps platform turns one-off model scripts into a repeatable, governed, observable process.
What MLOps actually means
MLOps is the application of DevOps principles to machine learning, adapted for the fact that ML systems depend on data and models, not just code. A traditional software system is defined by its code; an ML system is defined by code plus the data it trained on and the model artifact that resulted.
That extra dependency is why ML needs its own operational discipline — you must version and track data and models, not only source code, and you must monitor for data-driven failures that conventional software never has.
An MLOps platform is the tooling that makes this discipline practical across a team.
The problems it solves
Reproducibility. Without MLOps, a model is often the product of a notebook that no one can rerun — the data has changed, parameters were not recorded, and the result cannot be rebuilt. An MLOps platform records every run's code, data version, parameters, and metrics, so any model can be reproduced exactly.
This is the foundation everything else rests on.
Governance and traceability. When a model is in production, you must be able to answer: which version is live, what data trained it, who approved it, and how does it perform? A model registry with staged promotions (staging → production), approvals, and lineage answers these questions and is essential for audit and compliance.
The data-science-to-production gap. Models built in notebooks frequently die on the way to production because deployment is a manual, error-prone handoff. MLOps pipelines automate training, validation, packaging, and deployment so the path from experiment to live service is repeatable and fast.
Silent model decay. Unlike software bugs, a degrading model keeps returning answers — they just get worse as the world drifts away from the training data. Monitoring for data drift, concept drift, and performance decline catches this before it harms users.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
The core capabilities of a platform
A complete MLOps platform typically provides:
- Experiment tracking — log parameters, metrics, and artifacts for every training run so you can compare and reproduce them. MLflow and Weights & Biases are common here.
- Data and model versioning — version datasets and model artifacts alongside code (tools like DVC and built-in registries).
- Pipeline orchestration — define and run multi-step training workflows reproducibly (Kubeflow Pipelines, Metaflow, ZenML).
- Model registry — a governed catalog of model versions with stages, approvals, and lineage.
- Deployment and serving — package and serve models behind scalable endpoints (KServe, Seldon, cloud endpoints).
- Monitoring — watch live models for drift, data quality, and performance, often with dedicated observability tools.
Platforms differ in how much they bundle. Open-source backbones like MLflow and Kubeflow cover the lifecycle if you operate them; managed clouds like SageMaker, Vertex AI, Azure ML, and Databricks deliver the same capabilities as a service.
How it changes the way teams work
With an MLOps platform, ML work becomes a loop rather than a series of one-off heroics: data scientists experiment with tracked runs, the best model is registered and reviewed, a pipeline deploys it, monitoring watches it in production, and drift or new data triggers retraining — feeding back into the loop.
This continuous, automated cycle is what lets organizations run dozens or hundreds of models reliably instead of struggling to keep a handful alive. It also makes collaboration possible: tracked experiments, a shared registry, and reproducible pipelines mean teams build on each other's work instead of reinventing it.
When you need one
A single model maintained by one person can survive on careful manual process. The need for a platform grows with the number of models, the size of the team, and the cost of failure. Once you have several models, multiple contributors, or models making decisions that matter (fraud, pricing, risk, recommendations), the absence of MLOps shows up as outages, compliance gaps, and slow, error-prone deployments.
Most organizations adopt at least a tracking tool and a registry early, then add pipelines and monitoring as they scale.
Frequently Asked Questions
How is MLOps different from DevOps? MLOps applies DevOps automation and reliability practices to ML, but adds the handling of data and model artifacts. Where DevOps versions and tests code, MLOps must also version data and models, validate model quality, and monitor for data-driven decay — failures that conventional software does not have.
Do I need a single platform or can I assemble tools? Both work. Many teams assemble best-of-breed tools (MLflow for tracking, Kubeflow or ZenML for pipelines, a monitoring tool for production) connected by frameworks like ZenML. Managed platforms (SageMaker, Vertex AI, Databricks) bundle the lifecycle into one product, trading flexibility for less integration work.
What is a model registry and why does it matter? A model registry is the governed catalog of model versions, with stages (staging, production), approvals, and lineage. It answers which model is live, what trained it, and who signed off — essential for reliability and compliance. Without it, teams lose track of what is deployed.
How does an MLOps platform handle monitoring? It watches live models for operational issues (latency, errors), data drift (input distributions changing), and performance decay (quality dropping as data shifts). Managed platforms often include monitoring; open-source stacks pair with dedicated observability tools to catch silent degradation.
Does MLOps apply to LLM applications? The principles do, and the specialization is often called LLMOps. LLM apps add concerns like prompt management, generative-output evaluation, retrieval pipelines, and token-cost governance, but they still need experiment tracking, versioning, deployment, and monitoring — which modern MLOps platforms increasingly support.
What is the first thing to adopt? Start with experiment tracking and a model registry (MLflow is a common starting point). These give you reproducibility and governance quickly, which deliver immediate value, then add pipeline orchestration and production monitoring as your number of models and team size grow.
Sources
- MLflow official documentation
- Kubeflow and KServe documentation
- Amazon SageMaker documentation
- Google Vertex AI documentation
- Microsoft Azure Machine Learning documentation
- Databricks Mosaic AI documentation
- Weights & Biases, ZenML, Metaflow, and DVC documentation