
How do buying committees use synthetic data provided by vendors to validate AI model performance?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate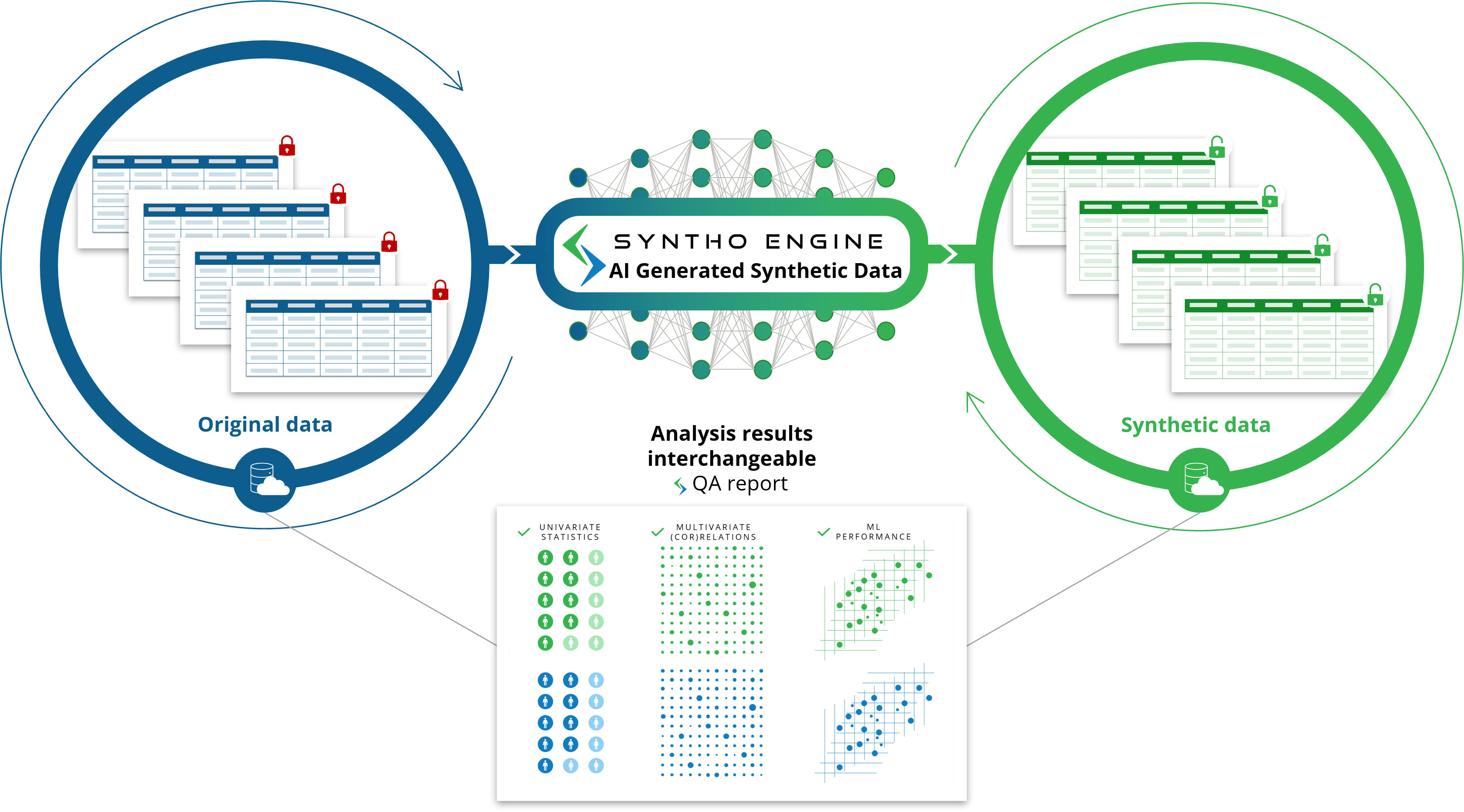
Direct Answer
In the 2027 RevOps reality, buying committees use synthetic data provided by vendors as a controlled, repeatable proxy for real-world data to validate AI model performance before deployment. They do this by designing specific test scenarios that mirror their own sales cycles, buyer personas, and pipeline stages, then comparing model outputs against known ground truths embedded in the synthetic data.
This approach allows committees to assess precision, recall, and bias without exposing sensitive customer data, while also stress-testing models against edge cases like churn signals or deal slippage. The result is a faster, safer validation process that directly answers the board’s question: “Will this AI actually improve our close rates or just add noise?”
The 2027 Buying Committee: Why Synthetic Data Became Essential
By 2027, the average B2B buying committee has grown to 11–16 stakeholders, according to Gartner’s latest buying journey research. These committees face a vendor consolidation wave—companies like Salesforce, HubSpot, and Gong are bundling AI features into core platforms, making it harder to evaluate point solutions.
At the same time, sales cycles have stretched to 9–14 months for enterprise deals, driven by the need to prove ROI before procurement signs off.
Synthetic data emerged as the answer to three core committee frustrations:
- Data privacy lockouts – Real customer data is often off-limits for vendor testing due to GDPR, CCPA, and internal compliance.
- Lack of historical context – New AI models have no track record in the buyer’s specific industry or deal size range.
- Inability to simulate failure – Committees need to see how models handle worst-case scenarios (e.g., a sudden 30% pipeline drop) without waiting for them to happen.
Vendors now ship synthetic datasets alongside their AI models, often generated using Gaussian copula or generative adversarial networks (GANs) trained on anonymized industry benchmarks. These datasets include labeled fields like deal_stage, days_in_stage, engagement_score, and win_probability, allowing committees to run controlled experiments.
How Committees Structure the Validation Process
The validation process follows a three-phase model that aligns with the committee’s decision-making cadence:
Phase 1: Scenario Design
The committee defines 5–10 test scenarios based on their actual pipeline data (aggregated and anonymized). For example:
- “Show us how the model predicts a $500K deal with a 6-month sales cycle and 3 executive sponsors.”
- “Simulate a churn event where the primary champion leaves the company.”
- “Test for bias across different verticals (e.g., healthcare vs. Manufacturing).”
Phase 2: Execution and Comparison
The vendor’s synthetic data is fed into the AI model, and outputs are recorded. The committee compares these against a baseline—either their own historical model (e.g., a Salesforce Einstein prediction) or a simple rule-based system. Key metrics include:
- F1 score for classification tasks (e.g., “will this deal close?”)
- Mean absolute error (MAE) for regression tasks (e.g., “expected deal value”)
- Bias variance across demographic or firmographic segments
Phase 3: Stress Testing
The committee deliberately introduces noise or missing data into the synthetic set (e.g., dropping 20% of engagement signals) to see if the model degrades gracefully. This is where Clari’s RevAI or Outreach’s Kaia models are often benchmarked.

👉 Quick Call with Kory White, Fractional CRO · See Kory on LinkedIn · CRO Syndicate
The Role of Ground Truth Labels in Synthetic Data
The most critical element of vendor-provided synthetic data is ground truth labels. These are the “correct answers” embedded in the dataset—for example, a synthetic deal record might have a field actual_outcome: won that the model should predict. Without accurate labels, the committee can’t measure model performance.
Vendors like Salesforce (with its Einstein GPT platform) and HubSpot (via Breeze AI) now provide synthetic datasets that include:
- Labeled deal stages (Prospecting → Qualification → Proposal → Negotiation → Closed Won/Lost)
- Timestamps for each stage transition
- Engagement metrics (email opens, meeting attendance, document views)
- Competitive win/loss reasons (price, feature gap, relationship)
- Churn probabilities for existing accounts
The committee’s job is to verify that these labels are consistent and representative of their own data distribution. They do this by running a distribution alignment test—comparing the synthetic data’s statistical properties (mean, variance, correlation) to their own anonymized data.
If the synthetic data shows a 10–15% deviation in key metrics like avg_deal_size or win_rate_by_industry, it’s rejected.
Common Pitfalls Committees Identify (and How Vendors Address Them)
Buying committees have become sophisticated at spotting synthetic data weaknesses. The top three issues in 2027 are:
1. Overfitting to Synthetic Patterns
Some models “memorize” the synthetic data’s quirks instead of learning generalizable rules. For example, a model might learn that deals with exactly 3 executive sponsors always close, ignoring the real-world nuance where sponsor quality matters more than quantity. Committees catch this by cross-validating with a holdout set of synthetic data the model hasn’t seen.
2. Missing Long-Tail Scenarios
Synthetic data often oversamples common scenarios (e.g., a $100K–$500K deal) and undersamples rare ones (e.g., a $10M enterprise deal with a 24-month cycle). Committees demand stratified synthetic datasets that include at least 5% rare events to ensure the model handles outliers.
3. Temporal Drift
A model validated on 2026 synthetic data may fail on 2027 market conditions. Vendors now offer time-series synthetic data that simulates quarterly shifts in buyer behavior. Committees test this by running the model on synthetic data from Q1 2026, Q2 2026, etc., and checking for performance decay over time.
Real Tools and Frameworks Committees Use
Three specific tools dominate the synthetic data validation workflow in 2027:
1. Gong’s Revenue Data Cloud
Gong provides synthetic datasets that mirror real conversation patterns, including call transcripts, email threads, and meeting summaries. Committees use these to validate AI models that predict deal health based on sentiment and keyword frequency. Gong’s synthetic data includes labeled sentiment scores (positive, neutral, negative) and objection categories (price, timeline, competitor).
2. Clari’s Revenue Data Platform
Clari offers synthetic pipeline data with 50+ fields, including deal_stage, forecast_category, commit_amount, and risk_score. Committees run Monte Carlo simulations on this data to see if the AI’s forecast accuracy holds up across 1,000+ iterations. Clari’s platform also includes a bias detection module that flags if the model performs differently on synthetic data from different regions or industries.
3. Winning by Design’s MEDDPICC Framework
The MEDDPICC framework (Metrics, Economic Buyer, Decision Criteria, Decision Process, Paper Process, Identify Pain, Champion, Competition) is now embedded in synthetic data schemas. Committees verify that the AI model correctly prioritizes deals with strong Champion and Economic Buyer signals, and that it doesn’t over-index on Metrics alone.
For example, a synthetic deal with a high Metrics score but weak Champion should be flagged as medium-risk, not high-risk.
FAQ
What is synthetic data in the context of AI model validation? Synthetic data is artificially generated data that mimics the statistical properties of real-world data without containing any actual customer information. In RevOps, vendors create synthetic datasets that include deal records, engagement metrics, and outcome labels, allowing buying committees to test AI models without exposing sensitive data.
How do committees ensure synthetic data is representative of their own pipeline? Committees run a distribution alignment test comparing the synthetic data’s mean, variance, and correlations to their own anonymized data. If key metrics like avg_deal_size or win_rate_by_industry deviate by more than 15%, the dataset is rejected.
Some committees also use Kolmogorov-Smirnov tests to check for statistical similarity.
What happens if the AI model performs well on synthetic data but fails in production? This is a known risk called synthetic drift. Committees mitigate it by running a 90-day real-world pilot on 10% of their pipeline after synthetic validation. They compare the model’s predictions to actual outcomes and flag any divergence.
If the model’s F1 score drops by more than 5% in production, it’s sent back for retraining.
Can synthetic data be used to test for bias in AI models? Yes, and it’s one of the primary use cases. Vendors now include demographic and firmographic fields in synthetic data, such as company_size, industry, region, and buyer_role. Committees check if the model’s predictions are consistent across these segments.
For example, a model that predicts a 20% lower win rate for manufacturing deals than for tech deals would be flagged for bias.
How do vendors generate synthetic data for RevOps models? Most vendors use generative adversarial networks (GANs) or variational autoencoders (VAEs) trained on aggregated, anonymized data from thousands of customers. Some also use rule-based generation with predefined distributions for fields like deal_size and cycle_length.
The best vendors provide metadata explaining the generation process and any assumptions made.
What are the legal implications of using synthetic data? Synthetic data is generally exempt from GDPR and CCPA since it contains no personally identifiable information (PII). However, committees should still require vendors to sign a data processing agreement (DPA) that confirms the synthetic data was generated from anonymized sources.
Some enterprises also run re-identification risk assessments to ensure the synthetic data can’t be reverse-engineered.
Sources
- Gartner: The B2B Buying Committee Has Grown to 11–16 Stakeholders
- Forrester: Synthetic Data for AI Model Validation in Enterprise Sales
- McKinsey: The State of AI in Sales 2027
- Gong Labs: How Synthetic Data Improves Revenue AI Accuracy
- Clari: Synthetic Pipeline Data for Forecast Validation
- Salesforce: Einstein GPT and Synthetic Data Generation
- HubSpot: Breeze AI and Data Privacy in RevOps
- Winning by Design: MEDDPICC Framework for Modern Buying Committees
- Bessemer Venture Partners: The 2027 Revenue Tech Stack
- SaaStr: How Enterprise Buying Committees Evaluate AI Tools
Bottom Line
Synthetic data is the only scalable way for 2027 buying committees to validate AI model performance without exposing real customer data or waiting for months to see results. By designing targeted test scenarios, running distribution alignment checks, and stress-testing for edge cases, committees can cut validation time from 6 months to 6 weeks.
The key is to treat synthetic data not as a perfect replica, but as a controlled experiment that reveals how the model will behave under known conditions—and to always follow up with a real-world pilot.
*Synthetic data validation for AI model performance in buying committees*