
What is a semantic cache and how much can it cut inference costs?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate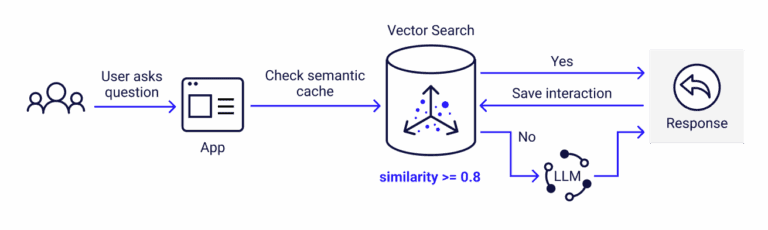
What is a semantic cache and how much can it cut inference costs?
Direct Answer
A semantic cache stores past LLM responses keyed by the *meaning* of the request rather than its exact text, so that a new query with the same intent — even if worded differently — returns the cached answer instead of hitting the model again. It works by embedding each incoming prompt, searching a vector store for a previously answered prompt above a similarity threshold, and serving the stored response on a hit.
For applications with repetitive or overlapping queries — FAQs, support bots, search, documentation assistants — a well-tuned semantic cache commonly serves anywhere from a small fraction to over half of traffic from cache, cutting token spend and latency proportionally on those requests.
The exact savings depend entirely on how repetitive your traffic is and how aggressively you tune the similarity threshold.
How a semantic cache works
A traditional cache (like Redis used as a key-value store) only returns a hit when the new key is *byte-for-byte identical* to a stored key. That is useless for natural language, where "What's your refund policy?" and "How do I get my money back?" are different strings but the same question. A semantic cache solves this by matching on meaning.
The flow is straightforward:
- Embed the incoming prompt. Convert the user's query into a vector using an embedding model (OpenAI
text-embedding-3, Cohere Embed, or an open model likebge/gteserved locally). - Search the cache. Query a vector store (Redis with vector search, Milvus, Qdrant, pgvector, or a purpose-built layer) for the nearest stored prompt embedding.
- Apply a similarity threshold. If the nearest match scores above your threshold (for example cosine similarity ≥ 0.95), it is treated as a cache hit and the stored response is returned. If not, it is a miss.
- On a miss, call the model and store the result. The new prompt embedding and its generated response are written back to the cache for future hits.
The cost win is direct: a cache hit costs one cheap embedding call plus a vector lookup instead of a full, expensive generation call. Embedding a query is typically orders of magnitude cheaper than generating a multi-hundred-token completion, and the lookup is sub-millisecond to low-millisecond.
How much can it actually save?
The honest answer is that savings scale with your cache hit rate, and the hit rate depends on your traffic. There is no universal percentage. The math is simple:
- If 40% of your requests hit the cache, you avoid roughly 40% of your generation calls — minus the small cost of embedding every query and storing misses.
- Each cached request still incurs an embedding call and a vector search, so the *net* saving per hit is the cost of a full completion minus the cost of one embedding plus a lookup.
Because completions are far more expensive than embeddings, the net saving per hit is close to the full generation cost. So a 40% hit rate translates to roughly a 35–40% reduction in generation spend on that traffic. Applications with highly repetitive queries — customer-support FAQs, internal knowledge bots, ecommerce product Q&A, documentation search — see the highest hit rates.
Applications where every query is unique and personalized (open-ended creative writing, per-user data analysis) see very low hit rates and benefit little.
The latency benefit is just as important as cost. A cache hit returns in milliseconds versus the seconds a generation can take, so the same mechanism that lowers spend also makes your fast path dramatically faster for repeated questions.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Tuning the similarity threshold
The threshold is the single most important knob, and it is a tradeoff:
- Too high (strict, e.g. 0.99): almost only near-identical prompts hit, so your hit rate — and savings — stay low, but you rarely serve a wrong cached answer.
- Too low (loose, e.g. 0.85): more queries hit the cache, boosting savings, but you risk false hits — returning a cached answer to a question that is similar in wording but different in intent (e.g. "cancel my subscription" vs "upgrade my subscription").
False hits are the real danger of semantic caching, because they return confidently wrong answers. Best practice is to start strict, measure both hit rate and false-hit rate on real traffic, and loosen carefully. Many teams add safeguards: scoping the cache per user or per tenant, including key context (selected model, parameters, retrieved documents) in the cache key, and excluding personalized or time-sensitive queries entirely.
When you should and should not use one
Good fits: FAQ and support bots, documentation and knowledge assistants, search and autocomplete, classification of recurring inputs, and any workload where many users ask overlapping questions. RAG systems benefit too, since users frequently re-ask the same questions of the same corpus.
Poor fits: highly personalized responses that depend on user-specific or real-time data, creative generation where variety is the point, and anything where a stale answer is harmful (live pricing, account balances, breaking news). For these, either skip semantic caching or restrict it tightly and add freshness controls (TTLs, invalidation on data change).
Tools that implement semantic caching
You can build one yourself with an embedding model plus a vector store, or use purpose-built tools:
- GPTCache — a popular open-source semantic cache that wraps LLM calls, handling embedding, storage, and similarity evaluation with pluggable backends.
- Redis — supports vector similarity search and is widely used as a semantic cache backend, often with LangChain's cache integrations.
- Vector databases (Milvus, Qdrant, Weaviate, pgvector) — serve as the similarity store underneath a custom cache.
- LangChain and LlamaIndex — provide caching abstractions, including semantic cache classes, that plug into these backends.
- AI gateways (Portkey, LiteLLM, Cloudflare AI Gateway) — increasingly offer semantic caching as a built-in feature so you get it without writing cache code.
Frequently Asked Questions
Is a semantic cache the same as prompt caching from model providers? No. Provider-side prompt caching (offered by OpenAI, Anthropic, and others) reuses the *computation* of a long, repeated prompt prefix to lower per-call cost and latency, but it still calls the model. A semantic cache avoids the model call entirely on a hit.
They are complementary — use prompt caching to cheapen the calls you do make and semantic caching to skip calls altogether.
What hit rate should I expect? There is no guaranteed number; it is entirely workload-dependent. Repetitive support and FAQ traffic can hit a large share of requests, while unique, personalized workloads may hit almost none. The only reliable approach is to measure hit rate on your own traffic before assuming any saving.
How do I avoid serving wrong answers from the cache? Use a conservative similarity threshold, include all answer-affecting context (model, parameters, retrieved docs, user/tenant) in the cache key, scope caches per tenant where appropriate, and exclude personalized or time-sensitive queries.
Monitor false-hit rate with sampled human or LLM-judge review and tighten the threshold if it climbs.
Does the embedding model choice matter? Yes. The cache only matches as well as its embeddings represent meaning. A stronger retrieval embedding model produces more reliable similarity judgments, while a weak one causes both missed hits and false hits.
Keep the same embedding model for writing and reading the cache, and re-embed if you change models.
Where should the cache live in my architecture? Centralizing it at an AI gateway or a shared service in front of your models gives consistent behavior, one place to tune thresholds, and shared hit rates across applications. Per-app caches are simpler to start with but fragment your hit rate and complicate invalidation.
How do I keep cached answers fresh? Set time-to-live (TTL) values appropriate to how fast the underlying knowledge changes, and invalidate entries when source data updates (for RAG, when the indexed documents change). For volatile data, either bypass the cache or use very short TTLs.
Sources
- GPTCache documentation — https://gptcache.readthedocs.io/
- Redis vector search and semantic caching — https://redis.io/docs/latest/develop/interact/search-and-query/advanced-concepts/vectors/
- LangChain LLM caching guide — https://python.langchain.com/docs/how_to/llm_caching/
- OpenAI embeddings documentation — https://platform.openai.com/docs/guides/embeddings
- Qdrant semantic cache use case — https://qdrant.tech/articles/
- Portkey semantic cache documentation — https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic