
What infrastructure do you need for fine-tuning versus RAG?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate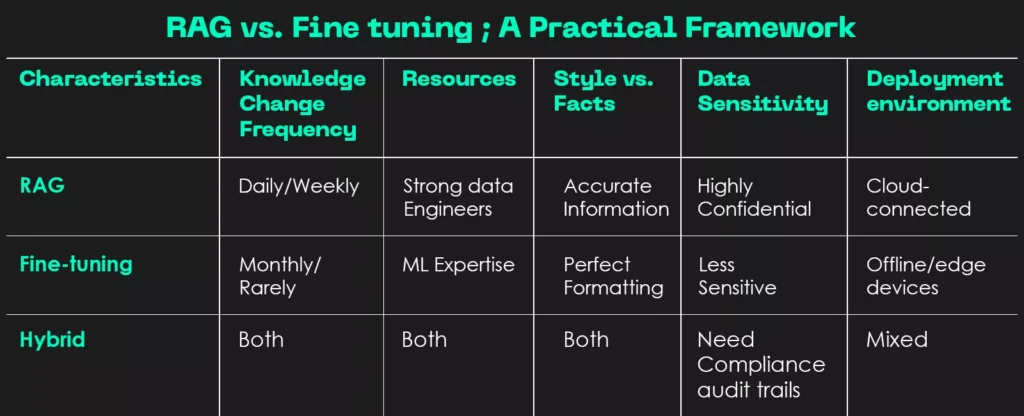
What infrastructure do you need for fine-tuning versus RAG?
Direct Answer
Fine-tuning and retrieval-augmented generation (RAG) solve different problems and therefore need very different infrastructure. Fine-tuning changes a model's weights, so it is GPU-and-data-heavy: you need access to capable GPUs (often multiple high-memory cards), a training framework, a dataset pipeline, experiment tracking, a model registry to store the resulting weights, and a serving stack to host the new model.
RAG leaves the model untouched and instead retrieves relevant context at query time, so it is data-and-retrieval-heavy: you need an embedding model, a vector database, an ingestion and chunking pipeline, an orchestration layer, and a way to keep the index fresh — but typically far less GPU than training.
In practice many production systems combine both: a lightly fine-tuned or off-the-shelf model serving behind a RAG pipeline. The deciding factor is whether you need to change *how* the model behaves (fine-tune) or *what* it knows right now (RAG).
What each approach actually does
Fine-tuning continues training a base model on your own examples so it internalizes a new style, format, domain vocabulary, or task behavior. The output is a new set of weights. This is the right tool when you need consistent tone, structured outputs, a specialized skill, or to teach behavior that prompting alone cannot reliably produce.
Because it modifies weights, fine-tuning is a training problem with all the infrastructure that implies.
RAG keeps the base model fixed and, at query time, retrieves relevant chunks of your data from a vector store and injects them into the prompt as context. This is the right tool when the model needs current, proprietary, or frequently changing knowledge — documentation, policies, product data — that you can update by re-indexing rather than re-training.
RAG excels at grounding answers in sources and reducing hallucination on factual queries.
Infrastructure for fine-tuning
Fine-tuning is fundamentally a GPU training workload, and its stack reflects that:
- GPUs: the biggest requirement. Full fine-tuning of large models needs multiple high-memory GPUs (such as NVIDIA H100/A100 class), while parameter-efficient methods like LoRA/QLoRA can fine-tune sizable open models on one or a few GPUs by training small adapter weights and quantizing the base.
- Training framework: libraries like Hugging Face Transformers + PEFT, Axolotl, Unsloth, or PyTorch with distributed training (FSDP, DeepSpeed) to run the actual optimization.
- Data pipeline: tools to collect, clean, format, and version the training dataset — often DVC or LakeFS for data versioning, since reproducibility depends on knowing exactly which data produced which weights.
- Experiment tracking: Weights & Biases or MLflow to log hyperparameters, loss curves, and evaluations across runs.
- Model registry and storage: a place to store and version the resulting weights — MLflow Model Registry, Hugging Face Hub, or a cloud bucket — with lineage back to the dataset.
- Serving stack: once trained, the new model must be served (often with vLLM, TGI, or Triton), which is its own GPU-bound deployment.
The cost profile is bursty and compute-heavy: expensive during training runs, then dominated by serving cost afterward. Managed services like Together AI, Modal, OpenAI's and others' fine-tuning APIs, or cloud GPU providers can absorb much of the GPU management.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Infrastructure for RAG
RAG is a retrieval and data-engineering workload, and its stack centers on getting the right context to the model:
- Embedding model: turns documents and queries into vectors. This can be a hosted API (OpenAI, Cohere, Voyage) or a self-hosted open model (BGE, E5, Nomic), needing only modest GPU or even CPU for smaller models.
- Vector database: stores and searches the embeddings — Pinecone, Weaviate, Qdrant, Milvus, or pgvector inside PostgreSQL. This is the heart of a RAG system.
- Ingestion and chunking pipeline: loaders, document parsers, chunkers, and embedding jobs that turn source data into indexed vectors, often orchestrated with LangChain, LlamaIndex, or a custom pipeline plus a scheduler.
- Orchestration / retrieval layer: the code that, per query, embeds the question, retrieves top-k chunks, optionally re-ranks them, builds the prompt, and calls the LLM. LangChain, LlamaIndex, or Haystack commonly fill this role.
- The LLM itself: any capable model via API or self-hosted server — RAG does not require you to train anything.
- Freshness and observability: a way to re-index changed data and tools like Langfuse, Arize Phoenix, or Ragas to evaluate retrieval and answer quality.
The cost profile is steady and retrieval-bound: dominated by embedding, vector-store, and inference API costs rather than training GPUs. RAG is usually faster and cheaper to stand up and to update than fine-tuning, because adding knowledge means re-indexing, not re-training.
Side-by-side: how the stacks differ
The two approaches diverge on almost every axis:
- GPU demand: fine-tuning is heavily GPU-bound for training; RAG needs little to no training GPU and only modest GPU for embeddings or self-hosted serving.
- What changes: fine-tuning changes model weights and behavior; RAG changes the context supplied at query time and the model's effective knowledge.
- Update cost: updating a fine-tuned model means another training run; updating RAG knowledge means re-embedding and re-indexing documents — far cheaper and faster.
- Core component: fine-tuning revolves around a training framework, experiment tracking, and a model registry; RAG revolves around an embedding model and a vector database.
- Best at: fine-tuning excels at consistent style, format, and learned tasks; RAG excels at current, factual, source-grounded knowledge with citations.
A practical rule: use RAG when the problem is knowledge (the model needs to know your latest docs or data) and fine-tuning when the problem is behavior (the model needs to respond in a specific way it cannot be reliably prompted into).
When to combine both
The two are not mutually exclusive, and mature systems often use both. You might fine-tune a model to reliably follow your output format, tone, or domain reasoning, then wrap it in a RAG pipeline so it answers from current, proprietary documents. In that architecture the fine-tuning infrastructure produces the served model, and the RAG infrastructure feeds it fresh context at query time.
Start with RAG because it is cheaper and faster to iterate, add fine-tuning only when prompting plus retrieval cannot achieve the behavior you need, and measure both with the same evaluation harness so you know which change actually moved quality.
Frequently Asked Questions
Should I start with fine-tuning or RAG? Start with RAG (and good prompting). It is cheaper, faster to update, and solves the most common need — grounding answers in your current data. Reach for fine-tuning only when you need consistent behavior, style, or a task that prompting plus retrieval cannot reliably deliver.
Do I need expensive GPUs for RAG? No. RAG's heavy components are an embedding model and a vector database, which need little or no training GPU. You only need modest GPU if you self-host the embedding model or the serving LLM; many teams use hosted APIs and skip GPUs entirely for RAG.
What is the cheapest way to fine-tune a model? Use parameter-efficient methods like LoRA or QLoRA, which train small adapter weights on a quantized base model and can run on a single GPU. Tools like Axolotl and Unsloth, or managed fine-tuning APIs, dramatically lower the GPU footprint versus full fine-tuning.
Can RAG replace fine-tuning entirely? Often yes for knowledge problems, but not for behavior. RAG supplies up-to-date facts but does not change how the model writes or reasons. If you need a specific format, tone, or learned skill, fine-tuning is the right tool, and the two combine well.
What is the core infrastructure difference in one sentence? Fine-tuning needs training GPUs, a data pipeline, experiment tracking, and a model registry; RAG needs an embedding model, a vector database, and an ingestion-plus-retrieval pipeline.
Sources
- Hugging Face PEFT documentation — https://huggingface.co/docs/peft
- Hugging Face fine-tuning guide — https://huggingface.co/docs/transformers/training
- LlamaIndex documentation — https://docs.llamaindex.ai/
- LangChain RAG documentation — https://python.langchain.com/docs/tutorials/rag/
- Qdrant documentation — https://qdrant.tech/documentation/
- Weights & Biases documentation — https://docs.wandb.ai/
- MLflow Model Registry — https://mlflow.org/docs/latest/model-registry.html