
The 10 Best Open-Source LLMs for Self-Hosting in 2027
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate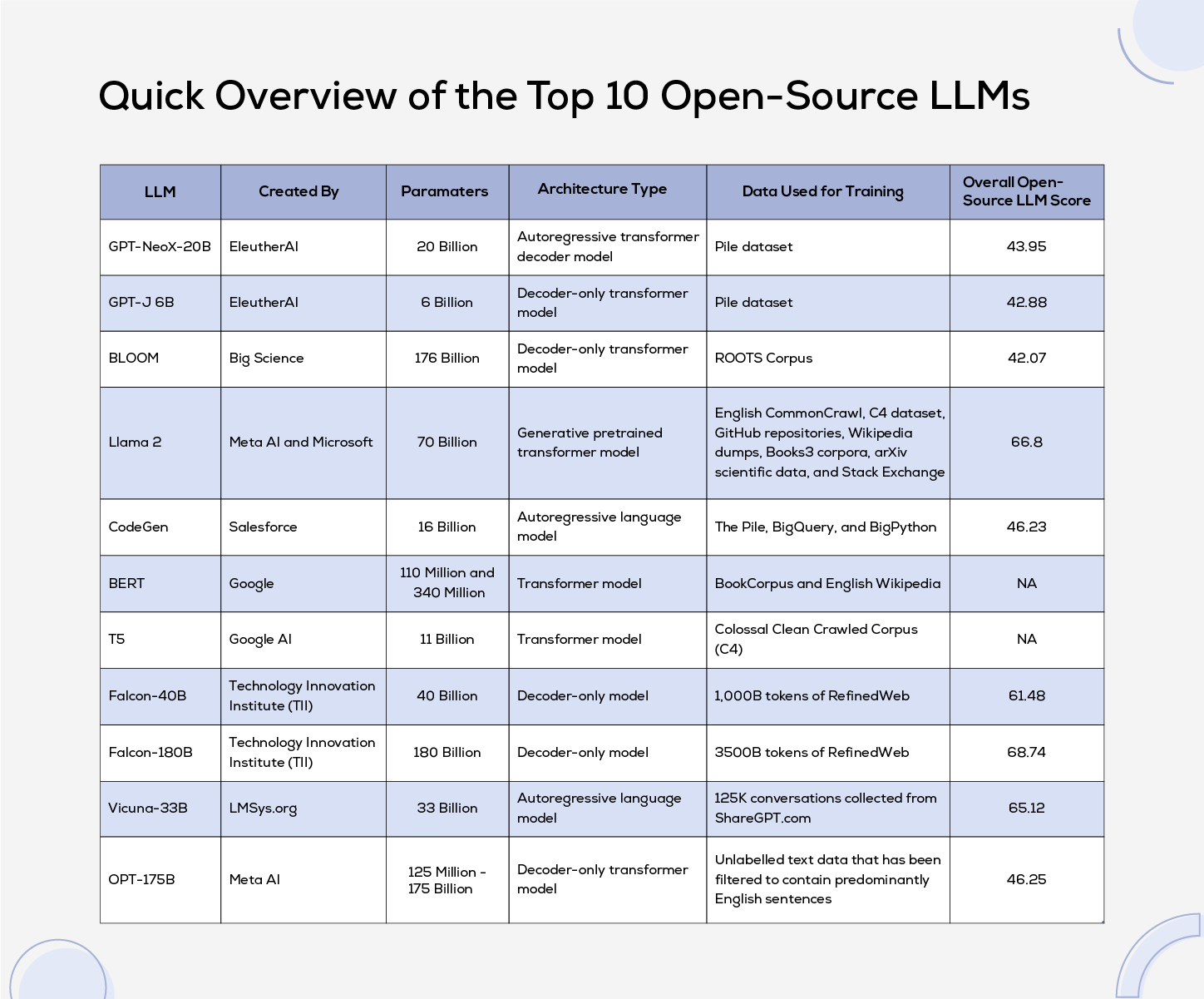
The 10 Best Open-Source LLMs for Self-Hosting in 2027
Self-hosting an open-weight large language model gives you control over data, predictable cost per token, and freedom from per-call API pricing. But "open source" spans a wide range — from permissive Apache-2.0 weights you can run anywhere, to community licenses with usage caveats.
The right model depends on your hardware budget, latency targets, and whether you need reasoning, long context, multilingual coverage, or tool use. This ranking covers the ten open-weight model families teams most commonly self-host in 2027, all of which publish downloadable weights and run on standard inference servers like vLLM, SGLang, or Ollama.
Direct Answer
Meta's Llama family is the best overall for self-hosting because it offers the widest range of sizes, the deepest ecosystem of fine-tunes and tooling, and proven production stability across thousands of deployments. Qwen is the best value because Alibaba ships Apache-2.0 weights across an unusually broad size ladder with strong reasoning, coding, and multilingual performance, letting you match a model exactly to your GPU budget.
Your choice depends on whether you prioritize ecosystem (Llama), permissive licensing and breadth (Qwen, Mistral), reasoning (DeepSeek, Qwen), or efficient small models for cheap hardware (Gemma, Phi).
How We Ranked These
We evaluated each model family on five criteria: license permissiveness (can you use it commercially without friction), quality per parameter (benchmark and real-world performance relative to size), size range (does it offer models that fit your GPUs), ecosystem and tooling (quantizations, fine-tunes, inference-server support), and specialization (reasoning, coding, long context, multilingual).
Because self-hosting is constrained by hardware, we weight quality-per-parameter and the availability of a size that fits common GPUs most heavily.
1. Meta Llama 🏆 BEST OVERALL
Llama is Meta's open-weight family and the de facto baseline for self-hosting. Its breadth — from small models that run on a single consumer GPU to large flagship models for multi-GPU servers — plus the enormous ecosystem of community fine-tunes, quantizations, and tooling makes it the safest default.
Nearly every inference server, quantization toolkit, and fine-tuning library supports Llama first.
What it is: Meta's flagship open-weight LLM family spanning small to large sizes, including instruction-tuned and reasoning-oriented variants. Strengths: largest ecosystem, broad size range, first-class tooling support, deep base of community fine-tunes. Best for: teams that want a proven, well-supported default with abundant resources.
Pricing/availability: weights free to download under Meta's community license; you pay only for the GPUs you run them on.
2. Qwen 💎 BEST VALUE
Qwen, from Alibaba, is one of the most complete open-weight families for self-hosting. It ships an unusually wide size ladder under permissive Apache-2.0 terms on many models, with strong coding, math, reasoning, and multilingual results. The breadth lets you pick a model that exactly matches your GPU budget rather than over-provisioning.
What it is: Alibaba's open-weight family with dense and mixture-of-experts variants, plus coder and reasoning lines. Strengths: Apache-2.0 on many models, excellent quality per parameter, strong multilingual and coding, very wide size range. Best for: teams that want permissive licensing and a model for every hardware tier.
Pricing/availability: weights free under Apache-2.0 (varies by model); self-host costs are GPU only.
3. Mistral
Mistral AI publishes capable open-weight models, including efficient dense models and mixture-of-experts designs that deliver strong throughput for their active-parameter count. Mistral's open models are popular for their clean licensing and efficiency, making them a strong European-built alternative to Llama and Qwen.
What it is: French lab's open-weight dense and MoE models. Strengths: efficient MoE inference, permissive Apache-2.0 on its open releases, strong general and coding performance. Best for: teams wanting efficient, permissively licensed models with good throughput.
Pricing/availability: open weights under Apache-2.0; managed API also offered separately.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
4. DeepSeek
DeepSeek released highly capable open-weight reasoning and general models that pushed strong performance at lower training and inference cost. Its mixture-of-experts architecture activates only a fraction of total parameters per token, giving large-model quality with more manageable serving costs for teams with the GPU memory to host it.
What it is: open-weight MoE models with strong reasoning and coding lines. Strengths: excellent reasoning quality, cost-efficient MoE inference, openly published weights. Best for: teams that need strong reasoning at lower effective compute.
Pricing/availability: open weights freely downloadable; large variants require substantial GPU memory.
5. Google Gemma
Gemma is Google's family of lightweight open models derived from the same research as Gemini. The small and mid sizes are designed to run efficiently on a single GPU or even capable laptops, making Gemma a favorite for edge and cost-sensitive self-hosting where a giant model would be overkill.
What it is: Google's lightweight open-weight models. Strengths: strong quality at small sizes, efficient on modest hardware, good documentation. Best for: edge and single-GPU deployments needing solid quality cheaply. Pricing/availability: open weights under Google's Gemma terms; free to download and run.
6. Microsoft Phi
Phi is Microsoft's family of small language models trained on heavily curated, "textbook-quality" data. The point of Phi is punching above its weight: small models that perform far better than their parameter count suggests, which is ideal when you want to serve many concurrent users cheaply or run on constrained hardware.
What it is: Microsoft's small, data-curated open models. Strengths: exceptional quality per parameter, tiny footprint, MIT-style permissive licensing on releases. Best for: cost-sensitive, high-concurrency, or on-device serving. Pricing/availability: open weights under permissive licenses; minimal GPU requirements.
7. Mixtral / Mistral MoE
Mixtral is Mistral's sparse mixture-of-experts line, which routes each token to a subset of expert networks. This gives the quality of a much larger model while only activating a portion of parameters per token, so throughput stays high. It remains a popular self-hosted choice where you have the VRAM to load all experts but want fast inference.
What it is: Mistral's open sparse-MoE models. Strengths: high throughput per quality, Apache-2.0, well-supported by inference servers. Best for: teams optimizing tokens-per-second on multi-GPU nodes. Pricing/availability: open weights under Apache-2.0.
8. NVIDIA Nemotron
Nemotron is NVIDIA's family of open models tuned for enterprise use and tightly optimized for NVIDIA's own inference stack (TensorRT-LLM, NIM microservices). For teams already standardized on NVIDIA hardware and software, Nemotron models slot neatly into an optimized serving path.
What it is: NVIDIA's open-weight models optimized for its inference stack. Strengths: tuned for NVIDIA GPUs, enterprise alignment, NIM packaging. Best for: NVIDIA-centric shops wanting hardware-optimized models. Pricing/availability: open weights; runs best on NVIDIA accelerators.
9. Falcon
Falcon, from the Technology Innovation Institute, was an early permissively licensed open model family and continues to release competitive weights. Falcon is valued for its clear licensing and its availability across a range of sizes, giving teams another vendor-neutral option outside the major labs.
What it is: TII's open-weight model family. Strengths: permissive licensing, multiple sizes, vendor-neutral provenance. Best for: teams wanting an alternative to US/China-origin models. Pricing/availability: open weights under permissive terms.
10. OLMo (Allen Institute for AI)
OLMo is AI2's fully open model — not just open weights but open training data, code, and logs. For research, auditing, and regulated environments where reproducibility and provenance matter, OLMo's radical transparency is unmatched, even if raw benchmark scores trail the largest frontier-adjacent open models.
What it is: Allen Institute's fully open (data + code + weights) model. Strengths: complete transparency and reproducibility, truly open license. Best for: research, auditing, and compliance-sensitive self-hosting. Pricing/availability: fully open and free to download.
Choosing the Right Model
Match the model to your hardware first. If you have a single mid-range GPU, start with Gemma, Phi, or a small Qwen or Llama. With a multi-GPU node, mid-size Llama, Qwen, or Mistral models hit a strong quality-cost balance.
For the highest reasoning quality and you can afford the VRAM, large DeepSeek or Qwen MoE models lead. Then layer licensing: if you need zero-friction commercial use, favor Apache-2.0 families (Qwen, Mistral, Mixtral, Falcon). Finally, serve everything through a production inference server — vLLM and SGLang for throughput, Ollama for simple single-node setups — and quantize with GGUF, AWQ, or GPTQ to fit memory.
Frequently Asked Questions
What does it cost to self-host an open-source LLM? The weights are free; your cost is GPU compute, plus engineering time. A small model can run on a single consumer or mid-range cloud GPU for a few hundred dollars a month, while large models need multi-GPU nodes that cost considerably more.
The break-even versus API pricing depends on your request volume — high, steady traffic favors self-hosting.
Is "open weights" the same as "open source"? Not exactly. Many popular models release downloadable weights under community licenses with some restrictions (Llama, Gemma), which is "open weights." Fully open-source models like OLMo also publish training data and code. Apache-2.0 models like Qwen and Mistral sit in between with permissive, low-friction terms.
Always read the specific license before commercial use.
Which inference server should I use to self-host? For production throughput, vLLM and SGLang are the standards, with continuous batching and paged attention. For simple single-node or local development, Ollama and llama.cpp are easiest. NVIDIA's TensorRT-LLM and Triton offer maximum performance on NVIDIA hardware.
The model you choose will be supported by all of these.
How do I fit a large model on limited GPU memory? Use quantization. Formats like GGUF, AWQ, and GPTQ shrink weights to 4-bit or 8-bit precision, often with minimal quality loss, cutting memory needs by half or more. Mixture-of-experts models also help because only a subset of parameters activates per token, though you still need memory to hold all experts.
Do open models support tool use and function calling? Yes. Modern open instruction-tuned models from Llama, Qwen, Mistral, and DeepSeek support structured outputs and function/tool calling. Quality varies by model and size, so test your specific agentic workflows.
Inference servers and frameworks like vLLM expose OpenAI-compatible tool-calling APIs to ease integration.
Can I fine-tune these models on my own data? Yes, and this is a major advantage of self-hosting. Parameter-efficient methods like LoRA and QLoRA let you fine-tune even large open models on a single GPU or a small node using frameworks like Hugging Face PEFT, Axolotl, or Unsloth, producing small adapter weights you serve alongside the base model.
Sources
- Meta — Llama models and documentation (llama.com / ai.meta.com)
- Alibaba — Qwen open-weight models (qwenlm.github.io / Hugging Face)
- Mistral AI — open models and licensing (mistral.ai)
- DeepSeek — open-weight model releases (deepseek.com / Hugging Face)
- Google — Gemma open models (ai.google.dev/gemma)
- Microsoft — Phi open models (azure.microsoft.com / Hugging Face)
- NVIDIA — Nemotron and NIM inference microservices (developer.nvidia.com)
- Allen Institute for AI — OLMo fully open models (allenai.org/olmo)
- VLLM project documentation (docs.vllm.ai)