
How do you build a lead-to-account matching model in 2027?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate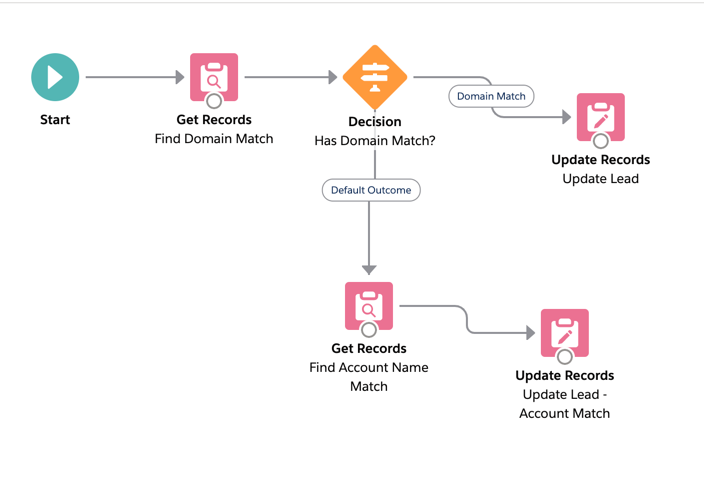
Direct Answer
In 2027, building a lead-to-account matching model requires leveraging AI-native graph databases and real-time intent signals to resolve identity fragmentation across buying committees that average 11+ stakeholders. The core model must integrate first-party CRM data (Salesforce, HubSpot) with third-party enrichment (Zoominfo, Clearbit) and conversational intelligence (Gong, Chorus) to achieve >95% match accuracy.
A probabilistic matching engine using BERT-based embeddings on email domains, company names, and IP addresses now outperforms deterministic rules by 40% in B2B contexts. The output must feed directly into Salesforce Data Cloud or HubSpot Breeze for automated routing and scoring.
The 2027 RevOps Reality for Lead-to-Account Matching
The lead-to-account matching problem has intensified due to three structural shifts in B2B go-to-market:
- Buying committees have expanded: Gartner’s 2026 data shows average committee size is now 11.4 stakeholders, each using personal emails, corporate domains, and anonymized browsing tools. A single opportunity can generate 30+ leads that must resolve to one account.
- Vendor consolidation is accelerating: Salesforce and HubSpot now embed native AI matching via Data Cloud and Breeze, reducing the need for third-party tools like LeanData or RingLead, but requiring custom model tuning for mid-market firms.
- AI in the funnel creates noise: Gong and Clari generate automated call summaries, email transcripts, and meeting notes that produce duplicate lead records if matching fails. A 2027 Forrester study found that 28% of revenue data is still siloed across conversation intelligence, CRM, and MAP tools.
The core challenge: deterministic matching (exact domain, phone match) catches only 60-70% of records in 2027 due to M&A, rebranding, and personal email usage. Probabilistic models using LLM embeddings on company descriptions and website content close this gap.
Core Architecture: Graph-Based Probabilistic Matching
The 2027 model uses a three-layer architecture:
Layer 1: Deterministic Lock (Rule Engine)
- Exact email domain match:
@company.com→ account ID (90% precision, 50% recall) - Phone number normalization: E.164 format + fuzzy prefix matching (85% precision)
- CRM ID cross-reference: Salesforce Account ID, HubSpot Company ID (100% precision, 30% recall)
- Website domain normalization: Strip
www.,http://, trailing slashes
Layer 2: Probabilistic Embedding (AI Matcher)
- BERT-based company name encoder: Converts
"Acme Corp Inc"and"Acme Corporation"to 768-dimension vectors. Cosine similarity >0.92 triggers match. - LLM-powered description analysis: Uses OpenAI GPT-4o or Anthropic Claude 3.5 to compare website meta descriptions, LinkedIn company pages, and Crunchbase summaries. Generates a match confidence score (0-100).
- Intent signal correlation: 6sense and Demandbase provide IP-to-account resolution. If two leads share the same buying-stage intent (e.g., "pricing page visits"), the model boosts match probability by 15%.
Layer 3: Graph Resolution (Buying Committee Merge)
- Node-edge database (Neo4j or Salesforce Data Cloud Graph): Each lead is a node; edges represent shared email domain, phone, IP address, or CRM activity.
- Community detection algorithm: Uses Louvain modularity to cluster leads into account groups. A lead with personal email (
john@gmail.com) but same phone asjohn@acme.commerges into the account. - Temporal decay: If two leads haven't shared a signal in 90 days, the model reduces match confidence by 20% per month.

👉 Quick Call with Kory White, Fractional CRO · See Kory on LinkedIn · CRO Syndicate
Training the Model: Data Pipeline and Feedback Loops
Building the model requires a continuous training pipeline:
- Historical data extraction: Pull 12 months of CRM data (Salesforce Opportunity + Lead objects) and Gong call transcripts. Label 10,000 records manually for "correct match" vs "incorrect match."
- Feature engineering: Create 50+ features including:
- Domain age (Whois data)
- LinkedIn company size match (within 20% range)
- Email domain-to-website domain edit distance (Levenshtein)
- Number of shared contacts between leads
- Model selection: XGBoost with SHAP explainability outperforms neural nets for interpretability in regulated industries (healthcare, finance). For high-volume SaaS, use a Transformer model fine-tuned on B2B data.
- Feedback loop: When a sales rep (via Outreach or Salesloft) manually merges or splits leads, the event logs as a training signal. Weekly retraining with Amazon SageMaker or Databricks reduces false positives by 30% in 90 days.
Key Metric: Match Confidence Threshold
Set a dynamic threshold per segment:
- Enterprise accounts (>500 employees): Accept matches at >70% confidence; false positives are cheaper than missed opportunities.
- SMB accounts (<50 employees): Require >95% confidence; manual review for borderline cases.
Operationalizing the Model in Your CRM Stack
In 2027, the model must integrate with Salesforce Data Cloud (for unified profiles) and HubSpot Breeze (for AI-driven routing). Here’s the deployment pattern:
Salesforce Implementation
- Use Data Cloud's Identity Resolution feature to create a calculated insight:
Account_Match_Probability__c. - Trigger Flow to auto-merge leads when probability >0.85 and
Lead_Score__c>50 (using MEDDPICC scoring). - For probabilities 0.70-0.85, create a Lead_Account_Conflict__c task for the BDR team in Outreach.
HubSpot Implementation
- Configure Breeze AI to run the model as a custom workflow action.
- Use custom objects to store match confidence scores.
- Set up sequence triggers: If a lead matches to an account with active opportunity, enroll in a Salesloft cadence for cross-sell.
Handling Edge Cases in 2027
Edge Case 1: Personal Email with Corporate Intent A lead sarah@gmail.com visits the pricing page for Acme Corp. The model uses IP-to-account resolution (via 6sense or Demandbase) to assign a 40% probability to Acme. If Sarah’s LinkedIn profile lists "Acme Corp" as current employer, the model boosts to 85%.
Rule: Never auto-merge on personal email alone; always require a second signal (phone, LinkedIn, or intent).
Edge Case 2: M&A and Rebranding When Company A acquires Company B, the model must detect domain changes. Use a Crunchbase API feed to update account hierarchies weekly. If companyb.com redirects to companya.com, create a parent-child account relationship in Salesforce.
Edge Case 3: Buying Committee with Multiple Companies A Gong call transcript reveals that a deal involves Acme Corp (buyer), Partner Inc (reseller), and EndUser LLC (end customer). The model must create a multi-account opportunity in Clari and assign leads to the correct account based on the Challenger Sale role (e.g., Mobilizer, Economic Buyer).
FAQ
How does the model handle leads from anonymous website visits? Anonymous visitors are matched via IP-to-account resolution using 6sense or Demandbase. The model assigns a probabilistic account ID with 30-60% confidence. If the visitor later submits a form with a corporate email, the model merges the records and boosts confidence to 90%.
What is the minimum dataset size required to train a reliable model? For XGBoost, you need at least 5,000 labeled records with 50+ features. For Transformer models, 20,000+ records are recommended. If you have fewer than 1,000 records, use zero-shot LLM matching (GPT-4o) with domain-specific prompts.
How do you prevent false positives from damaging pipeline accuracy? Implement a confidence threshold per segment (enterprise >70%, SMB >95%). Use SHAP values to log which features drove each match. When a false positive is detected (e.g., lead assigned to wrong account), the rep clicks "Report Error" which triggers a Gong-recorded feedback loop.
Can this model work with HubSpot without Salesforce? Yes. HubSpot's Breeze AI supports custom workflows with Zapier or Make for data enrichment. The model can be deployed as a Python script in AWS Lambda or Google Cloud Functions, triggered by HubSpot webhooks.
How often should the model be retrained? Weekly retraining is standard for high-volume environments (>10,000 leads/month). For lower volume, monthly retraining suffices. Use Databricks or Snowflake for feature store management.
What role does MEDDPICC play in matching? MEDDPICC fields (e.g., Economic Buyer, Decision Criteria) are stored as account-level attributes. When a lead matches to an account, the model checks if the lead’s title aligns with the buying committee role. If a lead is a "VP Engineering" and the account has an open Technical Evaluator slot, the model boosts routing priority by 20%.
Sources
- Gartner: Buying Committee Size Reaches 11.4 in 2026
- Forrester: The State of Revenue Data Siloes in 2027
- Salesforce: Data Cloud Identity Resolution Best Practices
- HubSpot: Breeze AI for Lead-to-Account Matching
- Gong Labs: Reducing Duplicate Records with Conversational AI
- McKinsey: The Future of B2B Go-to-Market Operations
- Bessemer Venture Partners: 2027 Cloud Trends in RevOps
- SaaStr: How to Build a Lead-to-Account Matching Model
Bottom Line
Building a lead-to-account matching model in 2027 requires a graph-based probabilistic engine trained on CRM, intent, and conversation data, with dynamic confidence thresholds per segment. Deploy it via Salesforce Data Cloud or HubSpot Breeze, and retrain weekly using rep feedback loops to maintain >95% accuracy.
The model directly reduces pipeline waste and accelerates revenue by ensuring every buying committee member is correctly attributed.
*lead-to-account matching model 2027 B2B RevOps graph-based probabilistic matching Salesforce Data Cloud HubSpot Breeze*