 Pulse Reviews and Analysis
Pulse Reviews and Analysis
How do you deploy AI models at the edge?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate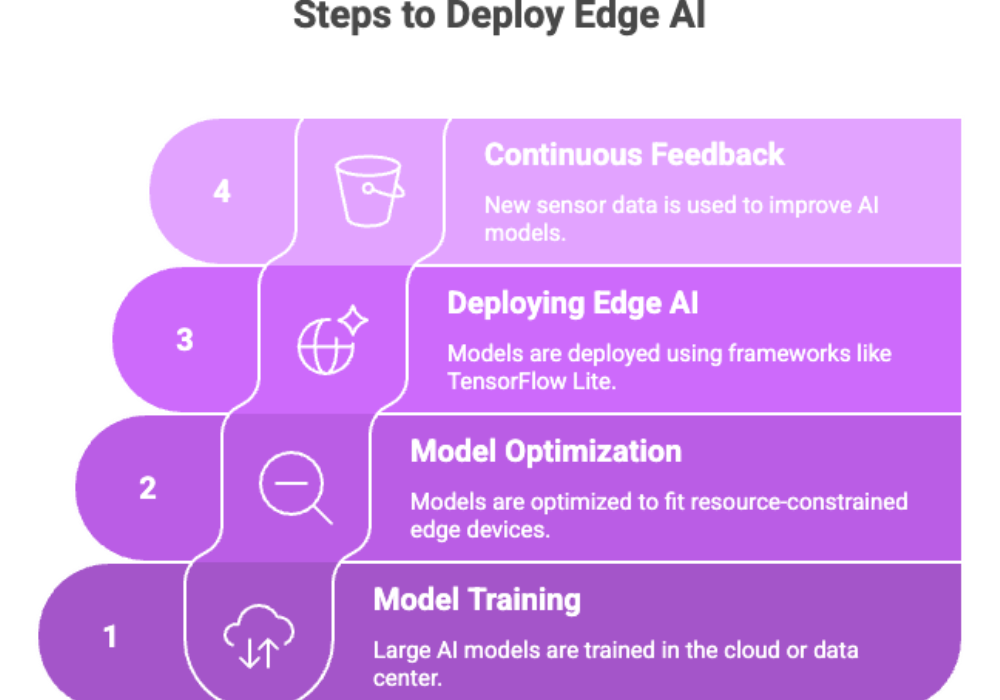
How do you deploy AI models at the edge?
Direct Answer
You deploy AI models at the edge by optimizing the model to fit constrained hardware, compiling it for the target accelerator, packaging it into a runtime that runs on-device, and managing it across a fleet with over-the-air updates and monitoring. The workflow is distinct from cloud deployment: instead of shipping a container to autoscaling servers, you shrink the model through quantization and pruning, convert it to an edge runtime format like ONNX, TensorRT, TensorFlow Lite, or Core ML, validate accuracy and latency on the actual device, and then push it to phones, cameras, gateways, or microcontrollers that may be offline, power-limited, and physically unreachable.
The practical stack pairs an optimization toolchain (TensorRT, ONNX Runtime, TF Lite, OpenVINO, Apache TVM) with hardware platforms (NVIDIA Jetson, edge TPUs, mobile NPUs, MCUs) and a device-management layer (AWS IoT Greengrass, Azure IoT Edge, Balena, or Edge Impulse) that handles deployment, OTA, and observability for thousands of devices.
Why edge deployment is fundamentally different
Cloud inference assumes abundant compute, fast networks, and easy redeploys. The edge assumes none of that. A model destined for a battery-powered camera or an industrial gateway has to run inside a few watts and a few hundred megabytes, often with no reliable connectivity, and once it ships you may not be able to touch the device for months.
That inverts the priorities: model size, latency, and power dominate, and the deployment system has to be robust to intermittent networks and partial failures.
The payoff is real. Running inference where the data is produced cuts round-trip latency to single-digit milliseconds, keeps sensitive data on-device for privacy and compliance, works when the network is down, and slashes the bandwidth cost of streaming raw video or sensor data to the cloud.
Those benefits are exactly why edge AI shows up in autonomous machines, smart cameras, wearables, and factory equipment.
Step 1: Optimize the model to fit the hardware
The first job is making a model small and fast enough for the target. The core techniques are well established:
- Quantization converts weights and activations from 32-bit floats to 8-bit integers (or lower), shrinking the model roughly 4x and speeding inference on integer-optimized hardware. Post-training quantization is fast; quantization-aware training preserves more accuracy when the naive conversion degrades it.
- Pruning removes redundant weights or whole channels, reducing compute and size.
- Knowledge distillation trains a small "student" model to mimic a larger "teacher," capturing most of the accuracy in a fraction of the parameters.
- Architecture choice matters upstream: families like MobileNet, EfficientNet, and YOLO-Nano are designed for edge efficiency from the start.
The non-negotiable rule is to measure accuracy after every optimization. Quantization that drops accuracy below your threshold is a regression, not a win, so you benchmark the optimized model against a held-out set before it goes anywhere near a device.
Step 2: Compile for the target runtime and accelerator
A trained model in PyTorch or TensorFlow is not deployable as-is on most edge hardware. You convert it to a runtime that matches the device:
- TensorRT for NVIDIA Jetson and GPUs — aggressive kernel fusion and INT8/FP16 optimization.
- TensorFlow Lite (LiteRT) for Android, microcontrollers, and edge TPUs.
- Core ML for Apple devices, targeting the Neural Engine.
- ONNX Runtime as a portable, cross-hardware option with execution providers for many accelerators.
- OpenVINO for Intel CPUs, integrated GPUs, and VPUs.
- Apache TVM as a compiler stack that can target a wide range of exotic hardware.
Converting to ONNX as an intermediate format is a common pattern because it decouples your training framework from the deployment target, letting one exported model fan out to several runtimes.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Step 3: Choose the hardware tier
Edge is not one thing — it spans orders of magnitude in compute, and the platform you pick dictates everything upstream:
- Edge GPUs like NVIDIA Jetson (Orin family) run full vision pipelines with TensorRT and DeepStream; suited to robots, cameras, and industrial systems.
- Edge accelerators like Google Coral Edge TPU and Hailo modules deliver high inference-per-watt for vision at low cost.
- Mobile NPUs on phones run Core ML and TF Lite models on the device's neural engine.
- Microcontrollers (TinyML) — Arm Cortex-M class chips running TF Lite Micro — execute tiny models in kilobytes of RAM for always-on sensing.
Matching the model to the tier is the central design decision: a YOLO model belongs on a Jetson or Coral, a keyword-spotting model belongs on an MCU.
Step 4: Package, deploy, and manage the fleet with OTA
Getting a model onto one device is a demo; operating thousands of them is the real problem. A device-management layer handles deployment, versioning, and over-the-air updates:
- AWS IoT Greengrass and Azure IoT Edge run containers/components on edge devices and push model updates from the cloud, with offline operation and secure connectivity.
- Balena manages fleets of Linux edge devices with container-based OTA updates and remote access.
- Edge Impulse provides an end-to-end path from data to an optimized model deployed on MCUs and small Linux devices, abstracting much of the embedded complexity.
OTA must be atomic and reversible: deploy to a canary subset, verify health, roll forward gradually, and keep the previous version ready to roll back if accuracy or latency regress in the field.
Step 5: Monitor and close the loop
Once models are in the field you need observability that survives intermittent connectivity. Track on-device inference latency, throughput, resource use, and — where you can collect it — prediction confidence and ground-truth feedback to detect data drift as the real-world distribution diverges from training.
When drift or failures appear, you retrain in the cloud and push a new optimized model through the same OTA pipeline. This feedback loop is what turns a one-time deployment into a maintainable edge AI system.
Common pitfalls
- Skipping on-device validation. Latency and accuracy on your laptop are not what you get on the target chip; always benchmark on real hardware.
- Ignoring thermal throttling. Sustained inference heats edge devices, which then throttle and miss latency targets. Test under realistic duty cycles.
- Non-atomic updates. A half-applied OTA update can brick a device. Use platforms with atomic, reversible updates.
- No rollback path. Always keep the prior model version deployable so a bad release can be reversed remotely.
Frequently Asked Questions
What is the difference between edge and cloud AI deployment? Cloud deployment runs models on abundant, network-connected servers you can redeploy easily. Edge deployment runs models on constrained, often-offline devices where size, latency, and power dominate and updates must happen over the air.
Edge wins on latency, privacy, offline operation, and bandwidth cost.
Do I need to quantize my model for the edge? Almost always for microcontrollers and accelerators, and usually for edge GPUs too. INT8 quantization typically shrinks a model about 4x and speeds inference on integer-optimized hardware. Validate accuracy afterward and use quantization-aware training if post-training quantization degrades results.
Which runtime should I target? Use TensorRT for NVIDIA Jetson, TensorFlow Lite for Android/MCUs/edge TPUs, Core ML for Apple devices, OpenVINO for Intel, and ONNX Runtime when you need portability across accelerators. Exporting to ONNX first lets one model fan out to multiple runtimes.
How do I update models on devices already in the field? Use a device-management platform — AWS IoT Greengrass, Azure IoT Edge, Balena, or Edge Impulse — that supports atomic, reversible over-the-air updates. Deploy to a canary subset first, verify health, roll forward gradually, and keep the previous version ready for rollback.
How do I monitor models running at the edge? Track inference latency, throughput, resource usage, and prediction confidence on-device, syncing summaries when connectivity allows. Watch for data drift by comparing field predictions against any ground truth you can collect, and trigger cloud retraining plus a new OTA rollout when drift appears.
Can large language models run at the edge? Increasingly yes — small, quantized LLMs (a few billion parameters or fewer) run on edge GPUs and high-end mobile NPUs using runtimes like llama.cpp, ONNX Runtime, and Core ML, often with 4-bit quantization. Larger models still require server-class hardware, so many systems run a small on-device model and fall back to the cloud for hard cases.
Sources
- NVIDIA Jetson and TensorRT documentation — https://developer.nvidia.com/embedded/jetson-modules
- TensorFlow Lite / LiteRT documentation — https://ai.google.dev/edge/litert
- ONNX Runtime documentation — https://onnxruntime.ai/docs/
- Apple Core ML documentation — https://developer.apple.com/documentation/coreml
- Intel OpenVINO documentation — https://docs.openvino.ai/
- AWS IoT Greengrass documentation — https://docs.aws.amazon.com/greengrass/
- Azure IoT Edge documentation — https://learn.microsoft.com/en-us/azure/iot-edge/
- Edge Impulse documentation — https://docs.edgeimpulse.com/
- Google Coral Edge TPU — https://coral.ai/docs/