
The 10 Best Semantic Caching Tools for LLM Apps in 2027
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate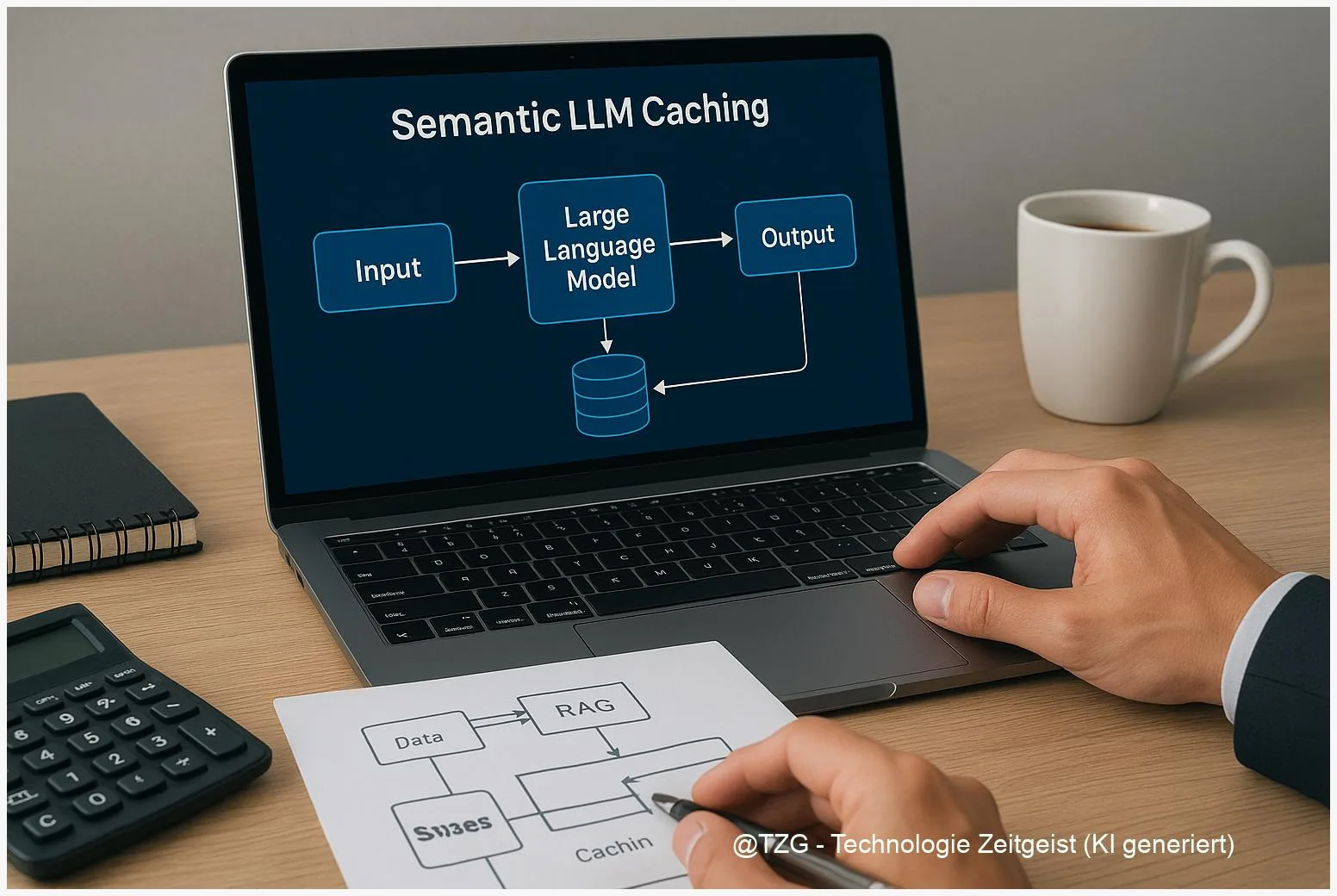
The 10 Best Semantic Caching Tools for LLM Apps in 2027
Every call to a large language model costs money and time. Yet in most production apps, a large share of requests are semantically similar to ones the system has already answered — paraphrased questions, repeated lookups, near-identical prompts. A semantic cache stores prior prompt-and-response pairs as embeddings and, when a new request arrives, checks whether a sufficiently similar prompt has already been answered.
If it has, the cached response is returned in milliseconds without ever touching the model. This cuts token spend, slashes latency, and reduces load on rate-limited provider APIs. This ranking covers the ten semantic caching tools that LLM engineering teams rely on most in 2027.
Direct Answer
GPTCache is the best overall semantic caching tool because it is the open-source, model-agnostic standard that pioneered the pattern, integrates with LangChain and LlamaIndex, and lets you mix and match embedding models, vector stores, and similarity thresholds. Redis (with its vector search and LangCache capability) is the best value because most teams already run Redis, so they get an in-memory semantic cache with no new infrastructure.
Your choice depends on whether you want a dedicated caching library, a gateway that caches for you, or a database you already operate doing double duty.
How We Ranked These
We evaluated each tool on five criteria: cache hit quality (how well it judges semantic similarity without returning wrong answers), latency (how fast the lookup and embedding step are), integration (how easily it drops into existing LLM stacks and frameworks), control (tunable similarity thresholds, eviction, and TTLs to manage staleness), and operability (managed options, observability, and scaling).
Because a bad cache hit can serve a wrong answer, we weight hit quality and control most heavily.
1. GPTCache 🏆 BEST OVERALL
GPTCache is the open-source library that defined semantic caching for LLM applications. It sits in front of any model API, embeds incoming prompts, searches a vector store for a semantically similar prior prompt, and returns the cached answer when similarity clears a threshold you set.
Its modular design lets you swap the embedding model, the vector store (FAISS, Milvus, and others), and the similarity evaluator independently.
What it is: dedicated open-source semantic caching library. Strengths: model-agnostic, framework integrations (LangChain, LlamaIndex), fully pluggable components, large community. Best for: teams that want a self-hosted, customizable cache layer. Pricing/availability: free and open-source.
2. Redis (Vector Search + LangCache) 💎 BEST VALUE
Redis is the in-memory data store that most stacks already run, and with its vector search capabilities it doubles as a high-speed semantic cache; Redis also offers LangCache, a managed semantic caching service. Because lookups happen in memory, hit latency is extremely low, and reusing infrastructure you already operate keeps cost and complexity down.
What it is: in-memory data store with vector search and a managed semantic-cache service. Strengths: sub-millisecond lookups, reuses existing infra, managed and self-hosted options. Best for: teams already running Redis who want caching without new systems.
Pricing/availability: open-source core; Redis Cloud and LangCache are paid managed tiers.
3. Portkey
Portkey is an AI gateway that, among many features, provides a built-in semantic cache. Because the gateway already proxies every model call, enabling caching is largely a configuration switch — you set a similarity threshold and TTL, and Portkey handles embedding, storage, and lookup transparently across providers.
What it is: AI gateway with built-in semantic and simple caching. Strengths: zero-code cache via the proxy, multi-provider, combined with routing and observability. Best for: teams that want caching as part of a broader gateway. Pricing/availability: open-source gateway; managed cloud with usage tiers.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
4. Helicone
Helicone is an LLM observability and gateway platform that offers caching alongside logging and analytics. Its cache can be enabled per request with simple headers, and because Helicone already logs every call, you get visibility into cache hit rates and savings out of the box.
What it is: LLM observability proxy with caching. Strengths: one-line header to enable, hit-rate analytics, broad provider support. Best for: teams that want caching tied to observability. Pricing/availability: open-source; managed cloud with free and paid tiers.
5. LiteLLM
LiteLLM is a popular open-source LLM proxy and SDK that unifies access to 100-plus providers behind the OpenAI API format, and it includes caching support backed by Redis, in-memory, or other stores, including semantic caching modes. It is a common foundation layer that teams extend with caching, routing, and budgets.
What it is: open-source LLM proxy/SDK with pluggable caching. Strengths: huge provider coverage, configurable cache backends, self-hostable. Best for: teams standardizing on a unified proxy who want caching included. Pricing/availability: free and open-source; paid enterprise tier.
6. Milvus / Zilliz Cloud
Milvus is a high-performance open-source vector database (offered managed as Zilliz Cloud) that serves as the storage and search engine underneath many semantic caches, including GPTCache. When your cache must hold millions of entries with fast approximate-nearest-neighbor search, a dedicated vector database like Milvus provides the scale and index tuning a general cache cannot.
What it is: vector database used as the cache's similarity-search backend. Strengths: scales to billions of vectors, tunable ANN indexes, managed option. Best for: very large caches needing serious vector search. Pricing/availability: open-source; Zilliz Cloud is paid managed.
7. MongoDB Atlas Vector Search
MongoDB Atlas Vector Search lets teams that store application data in MongoDB add semantic caching in the same database. You store prompt embeddings alongside cached responses and run vector similarity queries natively, avoiding a separate cache system and keeping cache entries close to your operational data.
What it is: vector search inside a managed document database. Strengths: consolidates cache with app data, managed and scalable, familiar query model. Best for: MongoDB-centric teams. Pricing/availability: part of MongoDB Atlas paid tiers.
8. Elasticsearch / OpenSearch
Elasticsearch and its open-source fork OpenSearch support dense-vector fields and k-NN search, so teams that already run them for logging or search can build a semantic cache on existing clusters. Combining keyword and vector matching also enables hybrid cache strategies that blend exact and semantic matching.
What it is: search engines with vector/k-NN capability used as a cache store. Strengths: reuse existing search infra, hybrid matching, mature operations. Best for: teams already operating Elasticsearch or OpenSearch. Pricing/availability: open-source (OpenSearch); Elastic offers paid managed tiers.
9. Canonical / Vector-store-backed custom caches with LangChain
LangChain ships caching abstractions (including semantic caching backed by vector stores) that let developers add a cache to an existing chain with a few lines of code. For teams already building on LangChain, this is the lowest-friction path: point the cache at a vector store you already use and set a similarity threshold.
What it is: framework-native caching abstraction over vector stores. Strengths: minimal code, works with many vector backends, fits existing LangChain apps. Best for: LangChain-based applications. Pricing/availability: free and open-source.
10. Cloudflare AI Gateway
Cloudflare AI Gateway is a managed proxy that sits between your app and LLM providers and offers caching, rate limiting, and analytics at the edge. Running on Cloudflare's global network, it can serve cached responses close to users, and enabling caching is a configuration option rather than custom code.
What it is: edge AI gateway with caching and analytics. Strengths: global edge, managed, combines caching with rate limiting and logging. Best for: teams wanting a managed edge proxy with caching. Pricing/availability: free tier with usage-based paid plans.
How to choose the right semantic cache
Start with where your similarity matters. If your app answers many paraphrased versions of the same questions (support bots, internal Q&A), semantic caching delivers large savings and you should invest in a dedicated, tunable layer like GPTCache or a vector-database-backed cache. If you mostly see exact repeats, a simple key-value cache may suffice.
Next, weigh build-versus-buy: a gateway like Portkey, Helicone, or Cloudflare gives you caching with almost no code, while GPTCache or a LangChain cache gives you maximum control over thresholds and eviction. Finally, mind correctness — set a conservative similarity threshold, add TTLs so cached answers do not go stale, and exclude personalized or time-sensitive prompts from caching entirely.
Frequently Asked Questions
What is the difference between semantic caching and standard caching?
A standard cache matches requests by exact key — identical bytes return the cached value. A semantic cache matches by meaning: it embeds the prompt and returns a cached response when a previous prompt is similar enough, so "What's your refund policy?" and "How do I get a refund?" can hit the same entry.
How much can semantic caching reduce LLM costs?
It depends entirely on how repetitive your traffic is. Apps with high prompt redundancy — FAQ bots, internal assistants — can avoid a large fraction of model calls, while apps where every prompt is unique see little benefit. Measure your cache hit rate before assuming savings; the value scales directly with it.
Can a semantic cache return a wrong answer?
Yes — if the similarity threshold is too loose, it may serve a cached response for a prompt that only looks similar. Mitigate this with a conservative threshold, by excluding personalized or fast-changing queries, and by adding TTLs so stale answers expire.
Do I need a vector database for semantic caching?
Not always. For small caches, an in-memory index or Redis vector search is enough. For caches holding millions of entries with strict latency goals, a dedicated vector database such as Milvus or Zilliz Cloud provides the scale and index tuning a lighter store cannot.
Should caching live in the application or in a gateway?
A gateway (Portkey, Helicone, Cloudflare AI Gateway, LiteLLM) centralizes caching across all apps and services with minimal code, which is ideal for multi-service environments. Application-level caching (GPTCache, LangChain) gives a single app fine-grained control. Many teams use both layers.
How do I keep cached answers from going stale?
Set time-to-live (TTL) values so entries expire, invalidate the cache when underlying data changes, and never cache prompts whose answers depend on the current time, the specific user, or fast-moving data.
Sources
- GPTCache documentation and GitHub repository (zilliztech/GPTCache).
- Redis documentation: vector search and LangCache semantic caching.
- Portkey documentation: AI gateway caching (simple and semantic).
- Helicone documentation: caching and observability.
- LiteLLM documentation: proxy caching backends.
- Milvus and Zilliz Cloud documentation: vector database and ANN indexing.
- MongoDB Atlas Vector Search documentation.
- Cloudflare AI Gateway documentation: caching and rate limiting.