 Pulse Reviews and Analysis
Pulse Reviews and Analysis
What is the difference between batch and real-time inference infrastructure?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate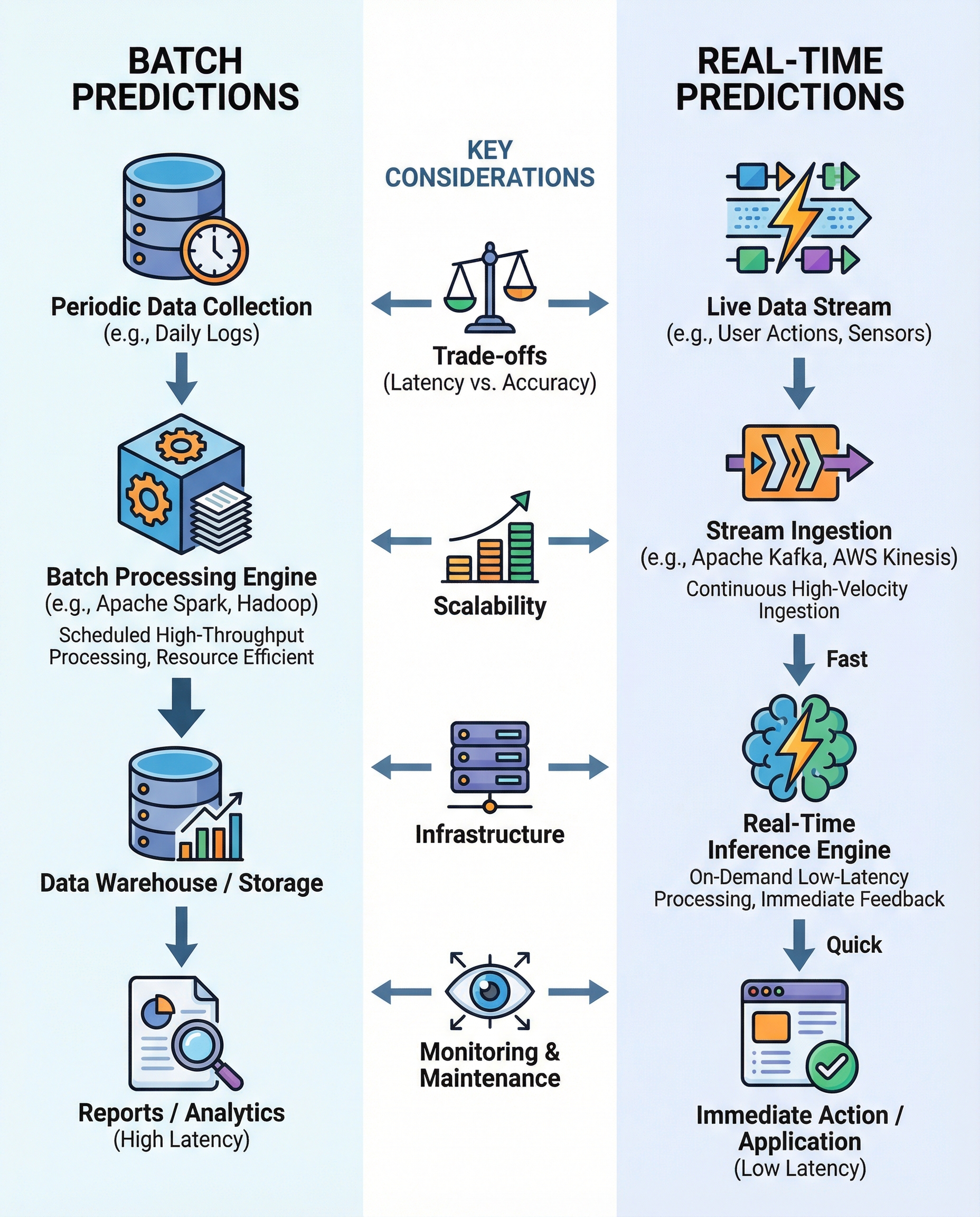
What is the difference between batch and real-time inference infrastructure?
Direct Answer
The difference comes down to when predictions are made and what you optimize for. Batch inference runs predictions on large groups of records on a schedule or on demand, optimizing for throughput and cost — it tolerates minutes or hours of delay, so it uses queues, distributed compute, and spot/preemptible GPUs to process millions of records cheaply.
Real-time (online) inference serves predictions one request at a time, synchronously, optimizing for low latency — it uses always-on serving endpoints, autoscaling, load balancing, and warm capacity so each response comes back in milliseconds to a few seconds. The same model can be served both ways; what changes is the surrounding infrastructure.
Many production systems use both, and a third "streaming" pattern sits in between for continuous near-real-time scoring.
The fundamental distinction
Batch and real-time inference answer different questions. Batch asks "score all of these records by the time we need the results," while real-time asks "score this one record right now while a user or system waits." That timing requirement cascades into every infrastructure decision — how compute is provisioned, how requests arrive, how you scale, and how you control cost.
Batch inference infrastructure
Batch inference processes data in bulk. A pipeline reads a large dataset, runs it through the model in parallel across many workers, and writes predictions to a database, data warehouse, or object store for later use. Because nothing waits on an individual prediction, the infrastructure is tuned for maximum throughput per dollar.
- Triggering: scheduled (e.g., nightly) via an orchestrator like Apache Airflow, Prefect, or Dagster, or on demand when a dataset lands.
- Compute: distributed and elastic — Apache Spark, Ray, or Kubernetes jobs — spinning up many workers, processing, and shutting down. Because latency does not matter, batch jobs can run on cheap spot/preemptible GPUs.
- Batching: large batch sizes maximize GPU utilization, since you can pack many records per forward pass.
- Output: results are persisted (warehouse, feature store, object storage) and consumed later by applications or dashboards.
Typical uses include nightly recommendation refreshes, scoring an entire customer base for churn, generating embeddings for a whole document corpus, and large-scale offline LLM processing.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Real-time inference infrastructure
Real-time inference serves predictions synchronously through an API. A request arrives, the model runs, and a response returns immediately, so the infrastructure prioritizes low and predictable latency and high availability.
- Serving: an always-on model server such as NVIDIA Triton, vLLM, TensorFlow Serving, TorchServe, or KServe exposes an endpoint behind a load balancer.
- Scaling: autoscaling adds and removes replicas with traffic, with warm capacity (min-replicas) to avoid cold starts on latency-critical paths.
- Dynamic batching: servers batch concurrent requests for a few milliseconds to improve GPU efficiency without materially hurting latency — a key technique that lets real-time systems approach batch-like utilization.
- Reliability: health checks, redundancy across zones, and graceful degradation, because the endpoint is on the critical path of a live application.
Typical uses include fraud scoring at transaction time, live recommendations, search ranking, and interactive LLM chat and copilots.
Key tradeoffs side by side
The two patterns optimize for opposite ends of the latency-cost-throughput triangle.
- Latency: batch tolerates minutes to hours; real-time targets milliseconds to a few seconds.
- Cost: batch is cheaper per prediction (big batches, spot GPUs, no idle capacity); real-time costs more because you keep capacity warm and run smaller, latency-bound batches.
- Throughput vs. Responsiveness: batch maximizes records-per-hour; real-time maximizes responsiveness per request.
- Failure handling: a failed batch job can simply be retried; a failed real-time request directly affects a user, so resilience and redundancy matter more.
- Scaling pattern: batch scales out for a job then scales to zero; real-time scales continuously with live traffic.
Streaming inference: the middle ground
Between the two sits streaming (or micro-batch) inference, where predictions are made continuously on events as they arrive — not on a fixed schedule like batch, but not strictly one-request-synchronous like online serving either. A streaming platform such as Apache Kafka or Amazon Kinesis feeds events into a processor (often Apache Flink or Spark Structured Streaming) that scores them in near real time and writes results downstream.
This pattern suits continuous workloads like real-time anomaly detection and IoT scoring, combining the always-on nature of real-time with the high-volume efficiency of processing events in small groups.
How to choose between them
Pick real-time when a human or system is waiting on the result and the freshest possible prediction matters — chat, fraud checks, live personalization, interactive copilots. Pick batch when predictions can be computed ahead of time or in bulk and consumed later — periodic scoring, embedding generation, offline analytics, large-scale document processing.
Choose streaming when data arrives continuously and you need fresh predictions within seconds but not synchronous request/response. In practice, mature platforms run all three: a batch pipeline to pre-compute and embed, real-time endpoints for live requests, and streaming for continuous event scoring — often sharing the same model and feature definitions across patterns to keep results consistent.
Frequently Asked Questions
Can the same model be used for both batch and real-time inference? Yes. The trained model is the same artifact; only the surrounding infrastructure differs. For batch you wrap it in a distributed job that processes large datasets, and for real-time you load it into an always-on serving endpoint.
Teams keep a single model registry and consistent feature definitions so batch and online predictions agree.
Why is batch inference cheaper per prediction? Batch packs many records into large batches that fully utilize the GPU, runs only when there is work to do (then shuts down), and can use cheaper spot/preemptible instances because it tolerates interruptions and delay. Real-time keeps capacity warm and runs smaller latency-bound batches, so it has more idle and lower utilization, raising cost per prediction.
What is dynamic batching in real-time serving? Dynamic batching is when a serving system (like Triton or vLLM) holds incoming requests for a few milliseconds to group several together into one GPU forward pass. This improves hardware efficiency and throughput while adding only a tiny, bounded amount of latency — it lets real-time systems get some of batch's efficiency without breaking their latency budget.
Where does streaming inference fit? Streaming sits between batch and real-time: it scores events continuously as they arrive from a stream (Kafka, Kinesis) using a processor like Flink or Spark Structured Streaming. It is ideal for continuous, high-volume workloads — anomaly detection, sensor data, live metrics — where you need predictions within seconds but not a synchronous request/response per call.
How do I decide which pattern a use case needs? Ask whether something is waiting on the prediction. If a user or live system needs an answer now, use real-time. If predictions can be precomputed or run in bulk and read later, use batch.
If data flows continuously and freshness within seconds matters, use streaming. Latency requirement, data arrival pattern, and cost sensitivity are the three deciding factors.
Do real-time endpoints need different monitoring than batch jobs? Yes. Real-time serving is monitored for latency (p50/p95/p99), error rate, throughput, and availability because it is on the live request path. Batch jobs are monitored for job success/failure, completion time, records processed, and data quality.
Both should track model performance and drift, but the operational SLOs are quite different.
Sources
- AWS — real-time vs. Batch inference (SageMaker docs) — https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html
- Google Vertex AI predictions (online vs. Batch) — https://cloud.google.com/vertex-ai/docs/predictions/overview
- NVIDIA Triton Inference Server — https://docs.nvidia.com/deeplearning/triton-inference-server/
- VLLM documentation — https://docs.vllm.ai/
- KServe documentation — https://kserve.github.io/website/
- Apache Flink documentation — https://nightlies.apache.org/flink/flink-docs-stable/
- Ray Data batch inference — https://docs.ray.io/en/latest/data/batch_inference.html
- Azure Machine Learning batch endpoints — https://learn.microsoft.com/azure/machine-learning/concept-endpoints-batch