 Pulse Reviews and Analysis
Pulse Reviews and Analysis
What is a vector index and how do HNSW and IVF differ?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate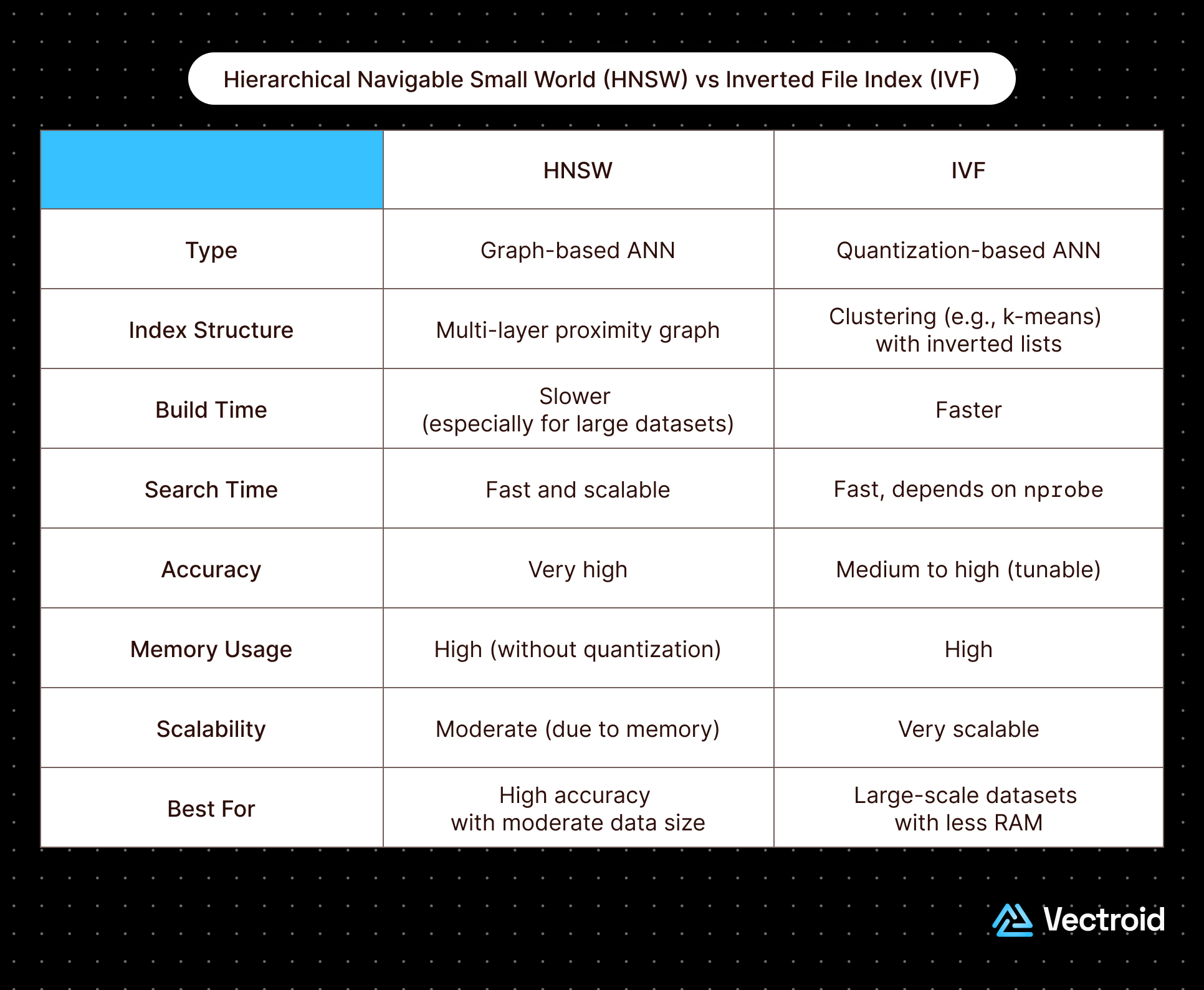
What is a vector index and how do HNSW and IVF differ?
Direct Answer
A vector index is a data structure that organizes high-dimensional embedding vectors so a system can find the nearest neighbors to a query vector in milliseconds instead of comparing it against every vector in the dataset. Because exact nearest-neighbor search is too slow at scale, vector indexes implement approximate nearest neighbor (ANN) search, trading a small amount of recall for enormous speed gains.
HNSW (Hierarchical Navigable Small World) builds a multi-layer graph you traverse to reach close vectors, giving very high recall and low latency at the cost of memory and slower builds. IVF (Inverted File Index) clusters vectors into buckets and searches only the buckets nearest the query, which uses less memory and builds faster but typically needs tuning and often quantization to match HNSW's recall.
In practice HNSW is the default for low-latency, high-recall workloads, while IVF (usually IVF-PQ) shines when memory or dataset size forces a more compact, partition-based approach.
What a vector index actually does
Modern AI applications turn text, images, and other data into embeddings — dense vectors of hundreds or thousands of dimensions where semantic similarity maps to geometric closeness. A retrieval-augmented generation (RAG) system, a recommendation engine, or a semantic search box all ask the same question: given this query vector, which stored vectors are most similar?
Answering that exactly means a brute-force scan computing distance to every vector, which is fine for thousands of items but collapses at millions or billions.
A vector index solves this by pre-organizing the vectors so the search can skip the vast majority of comparisons. The index accepts a tradeoff: instead of guaranteeing the true top-k neighbors, it returns the approximate top-k with measurable recall (the fraction of true neighbors found).
Tuning the index lets you move along a curve trading recall for speed and memory. Databases such as Pinecone, Weaviate, Qdrant, Milvus, pgvector, and the FAISS library all expose these indexes under the hood.
How HNSW works
HNSW organizes vectors into a layered graph of "small world" connections. The bottom layer contains every vector connected to its near neighbors; each higher layer is a sparser sample that acts like an express lane. A search starts at the top layer's entry point, greedily hops toward the query through long-range links, then descends layer by layer, refining toward the closest neighbors in the dense bottom layer.
Two parameters dominate HNSW behavior. M controls how many neighbors each node connects to (higher M means a richer graph, better recall, more memory). efConstruction governs build-time search breadth, and efSearch governs query-time breadth — raising efSearch increases recall at the cost of latency.
HNSW delivers excellent recall at very low latency and supports incremental inserts, which is why it is the default in Qdrant, Weaviate, pgvector's HNSW mode, and many others.
The cost is memory and build time: the full graph plus the original vectors usually live in RAM, and constructing the graph for large datasets is slower than building a flat partition. For most production RAG and search workloads under a few hundred million vectors, that cost is well worth the recall and latency.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
How IVF works
IVF (Inverted File Index) takes a clustering approach. During a training step it runs k-means to partition the vector space into nlist clusters, each with a centroid. Every vector is assigned to its nearest centroid's bucket.
At query time the index finds the nprobe centroids closest to the query and searches only the vectors inside those buckets, ignoring the rest.
Two parameters drive IVF. nlist sets how many clusters exist (more clusters mean smaller, more selective buckets). nprobe sets how many buckets to scan per query — raising nprobe improves recall but scans more vectors and costs latency.
Because IVF only searches a fraction of the data, it is fast and memory-lean relative to storing a full graph, and it scales well to very large datasets.
IVF is almost always paired with Product Quantization (PQ) to form IVF-PQ, which compresses each vector into a compact code so billions of vectors fit in memory. That compression sacrifices some precision, so IVF-PQ trades a bit more recall for dramatic memory savings. IVF needs a representative training set and a rebuild when the data distribution shifts significantly, which makes it less friendly to constant inserts than HNSW.
HNSW vs IVF: the practical differences
The choice usually comes down to recall-vs-memory and how dynamic your data is.
- Recall and latency: HNSW typically reaches higher recall at lower latency for small-to-medium datasets without quantization. IVF can match it but usually requires careful nlist/nprobe tuning and benefits from coarse-to-fine refinement.
- Memory: HNSW holds a graph plus full vectors in RAM, which is memory-hungry. IVF, especially IVF-PQ, is far more compact and is the go-to when datasets reach billions of vectors.
- Build time and updates: HNSW supports incremental inserts gracefully; IVF requires a training step and periodic rebuilds, so it favors more static datasets.
- Tuning surface: HNSW exposes M and efSearch; IVF exposes nlist and nprobe (plus PQ settings). Both let you dial the recall-speed tradeoff, but IVF's quantization adds another knob.
A common rule of thumb: default to HNSW for low-latency, high-recall search up to hundreds of millions of vectors; switch to IVF-PQ (or hybrid indexes like HNSW used as the coarse quantizer in FAISS) when memory or scale forces compression. Many engines, including FAISS and Milvus, let you combine techniques — for example IVF for partitioning with PQ for compression, or HNSW as the centroid search structure.
How vector databases expose these indexes
You rarely implement these algorithms yourself. FAISS (the Meta library) offers the broadest menu — Flat, IVF, IVF-PQ, HNSW, and combinations — and is the engine many databases embed. Qdrant, Weaviate, and pgvector default to HNSW for its recall and dynamic inserts.
Milvus supports HNSW, IVF variants, and DiskANN-style indexes for billion-scale data. Pinecone abstracts the index choice behind a managed service that picks and tunes for you. When you configure one of these, you are choosing and tuning exactly the HNSW or IVF parameters described above.
Frequently Asked Questions
Is HNSW always better than IVF? No. HNSW usually wins on recall and latency at small-to-medium scale, but IVF-PQ wins on memory and is often the only practical choice at billions of vectors. The right answer depends on dataset size, memory budget, and how often the data changes.
What is the difference between exact and approximate search? Exact search compares the query to every vector and guarantees the true nearest neighbors but is slow at scale. Approximate (ANN) search like HNSW and IVF skips most comparisons and returns near-exact results with measurable recall, which is far faster.
What is Product Quantization (PQ) and why pair it with IVF? PQ compresses each vector into a short code by splitting it into sub-vectors and quantizing each. Pairing it with IVF (IVF-PQ) lets billions of vectors fit in memory, at the cost of some precision, which is why it dominates very large deployments.
How do I tune HNSW for higher recall? Increase efSearch at query time for higher recall (more latency), and raise M and efConstruction at build time for a denser graph. There are diminishing returns, so measure recall against latency on your own data.
Which index should I start with for a RAG system? Start with HNSW, the default in Qdrant, Weaviate, and pgvector, because it gives high recall and low latency with easy inserts. Move to IVF-PQ only when memory or dataset scale makes HNSW impractical.
Sources
- FAISS wiki — https://github.com/facebookresearch/faiss/wiki
- HNSW paper (Malkov & Yashunin) — https://arxiv.org/abs/1603.09320
- Qdrant indexing documentation — https://qdrant.tech/documentation/concepts/indexing/
- Weaviate vector index documentation — https://weaviate.io/developers/weaviate/concepts/vector-index
- Milvus index types — https://milvus.io/docs/index.md
- Pgvector documentation — https://github.com/pgvector/pgvector