
The 10 Best Data Versioning Tools for ML in 2027
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate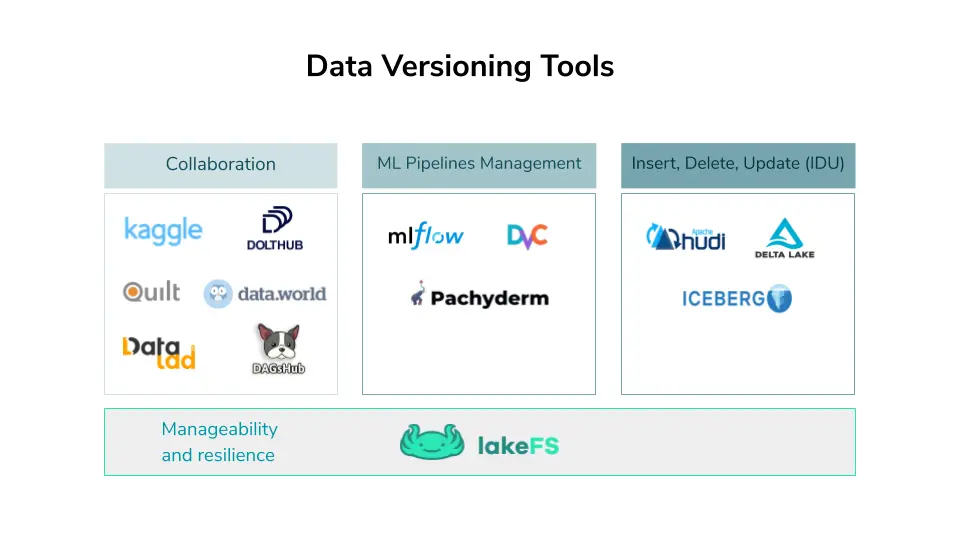
The 10 Best Data Versioning Tools for ML in 2027
Code without version control is unthinkable, yet data — the thing that actually shapes a model's behavior — is too often a pile of unversioned files in a bucket. That gap is where reproducibility dies: a model that scored well last quarter cannot be recreated because nobody knows exactly which data trained it.
Data versioning tools fix this by giving datasets the same rigor Git gives code — snapshots, diffs, branches, lineage, and the ability to pin a model to the exact data that produced it. They span Git-extensions, data lakehouse table formats, object-store versioning layers, and dataset platforms.
This ranking covers the ten data versioning tools ML teams rely on most in 2027 to make training reproducible, auditable, and collaborative.
Direct Answer
DVC (Data Version Control) is the best overall data versioning tool because it brings Git-native workflows to large datasets and models, integrating cleanly with your existing repo, remote storage, and pipelines so every model can be tied to the exact data and code that produced it.
lakeFS is the best value for teams on data lakes because it adds Git-like branching, commits, and rollback over object storage (S3, GCS, Azure) without copying data, and its open-source core is free. Your choice depends on whether you version files in Git, tables in a lakehouse, objects in a bucket, or curated datasets in a managed platform.
How We Ranked These
We evaluated each tool on five criteria: versioning model (snapshots, commits, branches, and diffs for data), scale and storage (how it handles large files and big datasets without duplication), lineage and reproducibility (linking data versions to code, pipelines, and models), integration (Git, cloud storage, lakehouses, and ML frameworks), and collaboration and cost (branching for teams, access control, and open-source vs.
Managed pricing). Because the entire point is recreating a model from its inputs, we weight lineage/reproducibility and scale most heavily.
1. DVC (Data Version Control) 🏆 BEST OVERALL
DVC extends Git to handle large datasets and models. It stores lightweight metafiles in your Git repo that point to the actual data in remote storage (S3, GCS, Azure, SSH, and more), so you version terabytes of data without bloating the repository. Beyond versioning, DVC defines reproducible pipelines that tie data, parameters, code, and outputs together, letting you recreate any model from its recorded inputs.
Its Git-native workflow, broad storage support, and pipeline reproducibility make it the most complete and widely adopted choice.
What it is: open-source Git extension for versioning data, models, and ML pipelines. Strengths: Git-native, storage-agnostic remotes, reproducible pipelines, links data to code, large ecosystem. Best for: teams wanting data versioning that lives alongside their code.
Pricing/availability: open-source, free; paid DVC Studio for collaboration.
2. LakeFS 💎 BEST VALUE
lakeFS brings Git-like operations — branch, commit, merge, revert — to data lakes on object storage, without copying the underlying data. You can branch a production dataset to experiment safely, commit a reproducible snapshot, and roll back instantly if a pipeline corrupts data.
Because it operates over S3/GCS/Azure with zero-copy branching and ships a free open-source core, it delivers powerful, scalable versioning for lake-scale data at the lowest effective cost — the best value for teams already on object storage.
What it is: open-source Git-like version control over data lakes on object storage. Strengths: zero-copy branching, atomic commits/rollback, scales to lake size, works with existing buckets. Best for: teams versioning large datasets on S3/GCS/Azure. Pricing/availability: open-source free; lakeFS Cloud managed tiers.
3. Delta Lake
Delta Lake is an open-source storage layer that adds ACID transactions, schema enforcement, and time travel to data lakes, letting you query or restore a table as of any prior version. Built around the Parquet-based Delta format and tightly integrated with Apache Spark and Databricks, it versions tables automatically as data changes, so you can pin training to a specific table version and reproduce results.
It is a cornerstone of the lakehouse pattern and excellent where data lives in tables.
What it is: open-source transactional table format with versioning and time travel. Strengths: ACID transactions, time travel, schema enforcement, strong Spark/Databricks integration. Best for: lakehouse teams versioning tabular data. Pricing/availability: open-source free; managed via Databricks.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
4. Apache Iceberg
Apache Iceberg is an open table format for huge analytic datasets that, like Delta, provides snapshots, time travel, and schema evolution with ACID guarantees. Its engine-neutral design works across Spark, Trino, Flink, and many warehouses, making it a popular choice for organizations that want versioned tables without lock-in to a single processing engine.
For ML, Iceberg snapshots give you reproducible, point-in-time training data at warehouse scale.
What it is: open, engine-neutral table format with snapshots and time travel. Strengths: broad engine support, snapshots/time travel, schema evolution, vendor-neutral. Best for: teams wanting versioned tables across multiple query engines. Pricing/availability: open-source, free.
5. Git LFS
Git LFS (Large File Storage) is the simplest, most familiar way to version larger files in Git by replacing them with pointers and storing the contents on an LFS server. For teams whose datasets are moderate in size and who want zero new tooling, it keeps data versioning entirely within the Git workflow they already know.
It does not scale to terabytes or provide pipeline lineage like DVC, but for small-to-medium datasets it is a low-friction starting point.
What it is: Git extension for versioning large files via pointers. Strengths: native Git workflow, trivial to adopt, widely supported. Best for: small-to-medium datasets already managed in Git. Pricing/availability: open-source free; storage/bandwidth via host (GitHub/GitLab).
6. Hugging Face Datasets (Hub + git-based versioning)
The Hugging Face Hub versions datasets as Git repositories (with LFS for large files), giving every dataset commit history, branches, and an easy load path through the datasets library. It is the de-facto home for sharing and versioning ML datasets in the open community, with dataset cards documenting provenance and usage.
For teams building on public or shared datasets — and for versioning their own — it combines versioning with discoverability and easy loading.
What it is: Git-based dataset hosting and versioning on the Hugging Face Hub. Strengths: Git+LFS versioning, easy loading, dataset cards, huge community. Best for: teams sharing or consuming community ML datasets. Pricing/availability: free public; paid private and enterprise tiers.
7. Pachyderm (HPE)
Pachyderm combines data versioning with data-driven pipelines: it versions data like Git (commits, branches) and automatically reprocesses only the changed data through pipelines, providing strong lineage from raw data to results. Built on containers and Kubernetes, it suits teams that need reproducible, incremental data processing at scale with full provenance.
Its tight coupling of versioning and pipeline execution makes lineage a first-class, automatic property.
What it is: data versioning plus data-driven, containerized pipelines with lineage. Strengths: automatic incremental processing, strong provenance, Kubernetes-native. Best for: teams needing reproducible large-scale data pipelines with lineage. Pricing/availability: open-source community edition; commercial enterprise.
8. Weights & Biases Artifacts
Weights & Biases Artifacts versions datasets, models, and other files within the W&B platform, tracking lineage automatically so you can see which data version fed which run and which model. Because it lives alongside W&B experiment tracking, you get end-to-end traceability — data to experiment to model — in one tool.
It is ideal for teams already using W&B who want dataset versioning integrated with their tracking rather than as a separate system.
What it is: versioned artifacts (data/models) with lineage inside W&B. Strengths: automatic lineage, integrated with experiment tracking, easy diffing. Best for: teams on W&B wanting unified data and run lineage. Pricing/availability: free tier; paid team/enterprise plans.
9. DagsHub
DagsHub is a collaboration platform for ML that layers on top of Git, DVC, and MLflow to give teams a GitHub-like home for code, data, models, and experiments together. It hosts DVC-versioned data with diffing and visualization, integrates experiment tracking, and adds data labeling and review — making it a hub for managing the full project, not just versioning.
For teams that want DVC's power with a collaborative web layer, it is a strong fit.
What it is: ML collaboration platform integrating Git, DVC, and MLflow. Strengths: unifies data/code/experiments, DVC-native, data diffing and visualization, collaboration. Best for: teams wanting a hosted home for DVC-versioned ML projects. Pricing/availability: free tier; paid plans.
10. Amazon S3 Versioning (with Glue/Lake Formation)
For teams standardized on AWS, S3 object versioning provides a baseline: enable versioning on a bucket and every object overwrite retains prior versions you can restore. Paired with AWS Glue Data Catalog and Lake Formation for cataloging and governance, it gives durable, low-effort version retention for training data without new tooling.
It lacks branching and pipeline lineage of purpose-built tools, but as a native, always-available safety net it is widely used as a foundation other tools build upon.
What it is: native object versioning on Amazon S3 plus AWS data catalog/governance. Strengths: zero new tooling on AWS, durable retention, restore prior versions, integrates with Glue/Lake Formation. Best for: AWS teams wanting baseline versioning of stored data.
Pricing/availability: pay for storage of versions; no separate license.
How to Choose the Right Data Versioning Tool
If your data is files and you want versioning that lives with your code and pipelines, choose DVC (optionally hosted via DagsHub). If your data is lake-scale objects, lakeFS gives you Git-like branching without copies. If your data is tabular in a lakehouse, Delta Lake or Apache Iceberg provide time travel and ACID guarantees.
For small datasets already in Git, Git LFS is the least-friction option. Teams on W&B should use Artifacts for integrated lineage, and AWS-centric teams can start with S3 versioning as a durable foundation.
Frequently Asked Questions
Why can't I just use Git for my datasets? Git is built for text and small files; committing gigabyte or terabyte datasets bloats the repo and slows everything down. Tools like DVC and Git LFS keep Git's workflow but store the actual data in external storage via pointers, while lakehouse formats version data in place at scale.
What is "time travel" in data versioning? Time travel is the ability to query or restore a dataset as it existed at a previous version or timestamp. Table formats like Delta Lake and Apache Iceberg keep version snapshots, so you can train on or audit data exactly as it was at a chosen point in time.
How does data versioning enable reproducibility? By pinning each model to the exact version of the data that trained it. When data, code, and parameters are all versioned and linked — as DVC pipelines or W&B Artifacts do — you can recreate any past model and explain precisely what produced it.
Do these tools duplicate my data and blow up storage? The good ones avoid it. LakeFS uses zero-copy branching, DVC deduplicates content and stores it once in remote storage, and table formats track changes rather than copying whole datasets. This keeps versioning affordable even at large scale.
How does data versioning relate to a model registry? They are complementary halves of reproducibility. Data versioning tracks the datasets; the model registry tracks model versions and links each one to the specific data version that trained it. Together they give end-to-end lineage from raw data to deployed model.
Which tool is best for a lakehouse architecture? Delta Lake (especially on Databricks/Spark) and Apache Iceberg (for engine neutrality) are the leading choices, both offering ACID transactions, schema evolution, and time-travel snapshots so you can reproduce training data at table scale.
Sources
- DVC (Data Version Control) documentation — https://dvc.org/doc
- LakeFS documentation — https://docs.lakefs.io/
- Delta Lake documentation — https://docs.delta.io/latest/index.html
- Apache Iceberg documentation — https://iceberg.apache.org/docs/latest/
- Git LFS — https://git-lfs.com/
- Hugging Face Datasets documentation — https://huggingface.co/docs/datasets/
- Pachyderm documentation — https://docs.pachyderm.com/
- Weights & Biases Artifacts documentation — https://docs.wandb.ai/guides/artifacts/
- DagsHub documentation — https://dagshub.com/docs/
- Amazon S3 versioning documentation — https://docs.aws.amazon.com/AmazonS3/latest/userguide/Versioning.html