
How do you route requests across multiple LLM providers?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate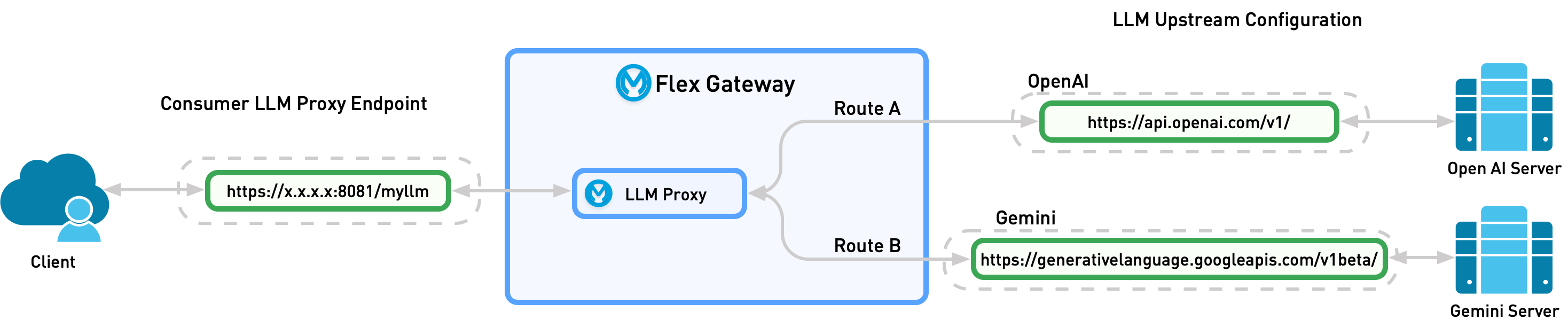
How do you route requests across multiple LLM providers?
Direct Answer
You route requests across multiple LLM providers by putting a gateway or router between your application and the models, so your code calls one unified endpoint and the router decides which provider and model to use, fails over when one is down, and retries on errors. The practical approach is to standardize on an OpenAI-compatible interface using a tool like LiteLLM (self-hosted proxy) or a managed router like OpenRouter, define a primary model plus fallbacks, configure load balancing across deployments, and route each request by cost, latency, or quality.
This decouples your application from any single vendor, raises availability, and lets you switch or blend models without touching application code.
Why multi-provider routing matters
Depending on a single model from a single provider is a reliability and cost risk. Providers hit rate limits, suffer outages, and deprecate models; prices vary by more than an order of magnitude across comparable models; and the cheapest model that still meets your quality bar changes from one request to the next.
Routing across providers turns those weaknesses into options. When one provider is rate-limited or down, traffic flows to another. When a request is simple, it goes to a cheaper, faster model; when it is hard, to a stronger one.
And because your application talks to a stable interface, you can adopt a new model the day it ships without a rewrite. The router is the layer that makes a multi-model strategy operationally real.
Start with a unified interface
The foundation of multi-provider routing is a common request format so your application never encodes provider-specific details. Most teams standardize on the OpenAI chat-completions schema because nearly every tool and provider speaks it or maps to it. LiteLLM is the de facto open-source layer here: its SDK and proxy translate calls for more than 100 providers — OpenAI, Anthropic, Google, AWS Bedrock, Azure, and self-hosted models — into one OpenAI-compatible interface.
Run it as a proxy and every service in your stack points at a single endpoint, with the provider chosen by configuration rather than code. Managed routers like OpenRouter offer the same idea as a hosted service: one API key, hundreds of models, no proxy to operate. Either way, the unified interface is what makes everything downstream — fallbacks, load balancing, smart routing — possible without per-call-site changes.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Configure fallbacks and failover
The first reliability win is automatic failover. You define an ordered list — a primary model and one or more fallbacks — and the router retries the next option when the current one fails, is rate-limited, or times out. With LiteLLM you specify fallback chains and retry policies; with OpenRouter, fallback across providers is built in.
Good failover handles three distinct cases: errors (5xx or connection failures), rate limits (429s, where backoff and a different deployment help), and context or content errors (where a different model entirely may succeed). Set sensible timeouts and a bounded retry count so a failing provider degrades gracefully instead of stalling every request.
Done well, an entire provider outage becomes a brief latency bump rather than an incident.
Load balance across deployments
Beyond failover, routers load balance across multiple deployments of the same or equivalent models to raise throughput and stay under rate limits. If you have several API keys, regions, or both a cloud and a self-hosted copy of a model, the router spreads requests across them — round-robin, weighted, or rate-limit-aware so it avoids deployments that are near their quota.
LiteLLM's proxy does this natively, tracking each deployment's limits and steering traffic to the one with headroom. Load balancing is what lets a high-traffic application exceed any single provider's per-key limits and keeps latency low under bursty load.
Route intelligently by cost, latency, or quality
The most valuable routing is per-request model selection. Not every request needs your most expensive model. Common strategies include: cost-based routing that sends simple requests to a cheap small model and only escalates hard ones; latency-based routing that prefers the fastest available model for interactive use; and quality-based or task-based routing that maps request types to the model best suited to them.
Some teams add a lightweight classifier or a "cascade" — try a cheap model first, and only call a stronger one if the cheap answer fails a check. The router enforces whatever policy you choose. Combined with fallbacks and load balancing, intelligent routing typically cuts spend substantially while preserving quality, because the expensive model is reserved for the requests that actually need it.
Add observability, budgets, and keys
A router is also the natural control plane for a multi-provider setup. Because every request flows through it, it is the right place to log tokens, cost, latency, and model per request, enforce budgets and rate limits per team or key, and issue virtual keys so individual services get scoped access and quotas without holding raw provider credentials.
LiteLLM's proxy provides spend tracking, per-key budgets, and virtual keys out of the box; managed routers expose usage dashboards. This turns routing from a reliability feature into a governance layer — you see exactly where spend goes and can cap a runaway service before it drains the account.
Frequently Asked Questions
What is the difference between a fallback and load balancing? Fallback is sequential: try the primary model, and only on failure try the next option, for resilience against errors and outages. Load balancing is parallel distribution: spread requests across multiple equivalent deployments at once for throughput and to stay under rate limits.
Mature setups use both — load balance across healthy deployments and fall back to alternatives when one fails.
Should I self-host a proxy or use a managed router? Self-hosting LiteLLM gives you full control, your own keys, on-prem logging, and the ability to include private or local models, at the cost of operating the proxy. A managed router like OpenRouter removes all infrastructure and gives instant access to many models with pay-as-you-go pricing, but you route through a third party.
Choose based on control, compliance, and operational appetite.
How do I route to the cheapest model that still works? Use cost-aware or cascade routing. Send the request to a cheap small model first, validate the answer with a quick check, and only escalate to a stronger model when the cheap one fails. Alternatively classify the request up front and map simple tasks to cheap models and hard tasks to premium ones.
The router enforces the policy so your application stays unchanged.
Will routing across providers break features that are provider-specific? It can if you rely on features only one provider supports, such as a particular tool-calling format or modality. A unified layer like LiteLLM maps common features across providers, but you should test that your prompts, tool definitions, and output parsing work on every model in a fallback chain.
Keep fallbacks to models of comparable capability for the task.
How does a router help control LLM cost? Because every request passes through it, the router can log spend per request, enforce per-key and per-team budgets, and cap or reject requests that exceed a limit — stopping runaway loops. Combined with cost-based routing that reserves expensive models for hard requests, it both reduces and governs spend from one place.
Sources
- LiteLLM documentation — routing, fallbacks, and load balancing (docs.litellm.ai)
- OpenRouter documentation — model routing and fallback (openrouter.ai/docs)
- LiteLLM proxy documentation — budgets, virtual keys, and spend (docs.litellm.ai/docs/proxy)
- Anthropic API documentation — models and messages API (docs.anthropic.com)
- OpenAI API documentation — chat completions schema (platform.openai.com/docs)
- AWS Bedrock documentation — multi-model access (docs.aws.amazon.com/bedrock)
- Portkey documentation — AI gateway and routing (portkey.ai/docs)
- Helicone documentation — gateway, observability, and cost (docs.helicone.ai)