
How do you choose an inference accelerator: GPU, TPU, or custom silicon?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate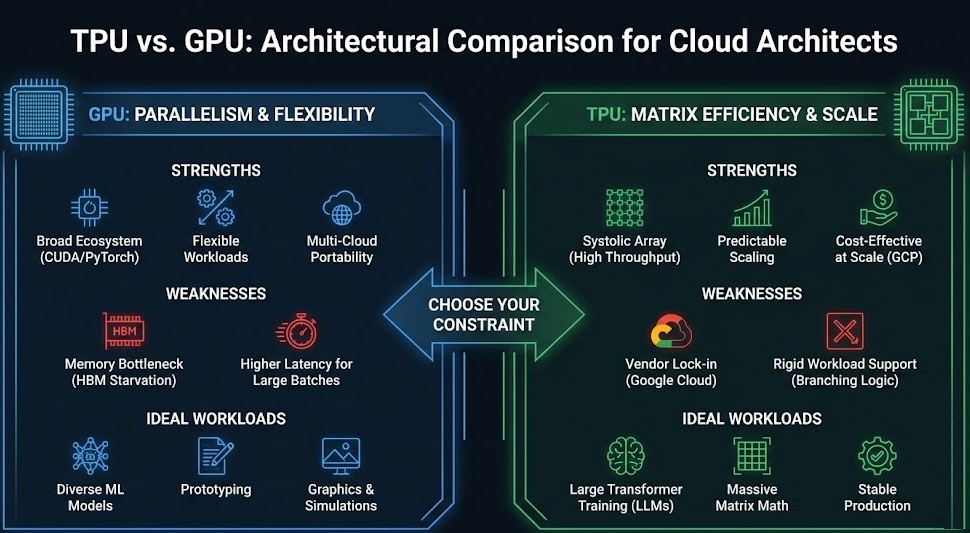
How do you choose an inference accelerator: GPU, TPU, or custom silicon?
Direct Answer
You choose an inference accelerator by matching the chip to the workload, the ecosystem, and the economics — not by chasing raw peak performance. GPUs (NVIDIA H100/H200/L40S, AMD MI300X) are the default: the broadest software support, the most flexibility, and the safest choice for diverse or evolving models.
TPUs (Google's tensor processing units) shine for large, stable workloads on Google Cloud where their cost-per-token and scale can beat GPUs. Custom silicon — AWS Inferentia/Trainium, Groq, and dedicated startups like Cerebras and SambaNova — can deliver the best price-performance or lowest latency for specific, high-volume inference, at the cost of ecosystem maturity and portability.
The right answer depends on your model, your volume, your latency target, your cloud, and how much engineering you can spend optimizing.
The core trade-off: flexibility versus efficiency
Every accelerator sits on a spectrum. At one end, GPUs are general-purpose parallel processors with a vast, mature software stack (CUDA, and increasingly ROCm) — they run almost anything and adapt as models change, but you pay for that generality. At the other end, custom silicon is purpose-built for specific tensor operations, squeezing out more performance-per-dollar or lower latency for the workloads it targets, but it is less flexible and tied to a narrower ecosystem.
TPUs sit in between: highly optimized for the matrix math of deep learning, with a solid but more constrained software stack. Choosing well means deciding how much you value flexibility and ecosystem versus raw efficiency for one workload.
GPUs: the safe default
GPUs from NVIDIA dominate AI inference because of software, not just silicon. CUDA, TensorRT-LLM, and broad framework support mean nearly every model, library, and serving stack (vLLM, TGI, Triton) runs on them out of the box. The lineup spans high-end H100/H200 for large LLMs, L40S and L4 for cost-efficient mid-size inference, and consumer-class cards for smaller workloads.
AMD's MI300X is a credible high-memory alternative with a maturing ROCm stack, attractive for memory-bound large models.
Choose GPUs when you run many different models, your models change frequently, you need the richest tooling, or you simply want the lowest-risk path. The downside is cost and supply: top GPUs are expensive and sometimes scarce, so right-sizing (using L40S/L4-class cards where you do not need H100s) is the main lever for controlling spend.
TPUs: scale and cost on Google Cloud
Google's Tensor Processing Units (TPUs) are custom accelerators designed specifically for the dense matrix operations of neural networks. On large, stable workloads — especially serving big models at high volume on Google Cloud — TPUs can offer strong throughput and competitive cost-per-token, and they scale into large pods for very large models.
They are well supported by JAX and TensorFlow, with growing PyTorch support via PyTorch/XLA.
Choose TPUs when you are on Google Cloud, your workload is large and steady enough to justify optimization, and you can work within the TPU software stack. The trade-off is portability and flexibility: TPUs are Google-specific, and getting peak performance can require more workload tuning than the plug-and-play GPU path.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Custom silicon: best price-performance for the right workload
A growing field of purpose-built inference chips targets specific advantages:
- AWS Inferentia (Inf2) — Amazon's inference chips, accessed via the Neuron SDK, aimed at lower cost-per-inference for high-volume serving on AWS. Trainium is the training counterpart.
- Groq LPUs — designed for extremely low-latency, high-throughput LLM inference, delivering very fast token generation for latency-sensitive applications.
- Cloud-specific AI chips — hyperscalers increasingly offer their own inference silicon to cut cost on their platforms.
- Specialized accelerators — vendors like Cerebras and SambaNova target large-model inference with novel architectures.
Custom silicon can win decisively on price-performance or latency for a specific, high-volume model you serve continuously. The cost is ecosystem maturity: you compile and optimize for that chip's toolchain, support for new model architectures may lag, and you accept lock-in to a vendor or cloud.
It pays off when your inference volume is large and stable enough that the optimization effort amortizes.
The decision factors that actually matter
Beyond the chip categories, these are the questions that drive the decision:
- Workload diversity. Many models or fast-changing ones favor GPUs; one stable high-volume model favors TPUs or custom silicon.
- Latency target. Strict real-time latency (chat, voice) may favor low-latency silicon like Groq or well-tuned GPUs; batch tolerance opens cheaper options.
- Volume and steadiness. High, predictable volume justifies optimizing for a specialized chip; spiky or low volume favors flexible, on-demand GPUs.
- Cloud and ecosystem. Your existing cloud often decides for you — Inferentia on AWS, TPUs on Google — because of integration and pricing.
- Software maturity. GPUs have the richest stack; specialized chips require their SDKs (Neuron, XLA) and may not support every model day-one.
- Memory needs. Large models are often memory-bound; high-memory GPUs (MI300X, H200) or scaled TPU pods matter more than raw compute.
- Engineering budget. Optimizing for custom silicon costs engineering time; GPUs minimize that effort.
How software and quantization change the math
Hardware choice is only half the picture — how you run the model often matters as much as which chip you run it on. The same GPU can serve several times more requests with an optimized server (vLLM, TensorRT-LLM, or TGI) than with naive inference, because techniques like continuous batching, paged attention, and speculative decoding dramatically raise throughput.
Quantization — running a model in 8-bit or 4-bit precision — can let a smaller, cheaper accelerator host a model that would otherwise need a top-tier card, shifting the cost equation entirely. This means you should never compare bare hardware in isolation: a well-optimized L40S deployment can beat an under-optimized H100 on cost-per-token, and an INT8 model on inexpensive silicon can outperform an FP16 model on premium hardware.
Before buying or migrating, exhaust software-level optimization on what you already have, because it is the cheapest performance you will ever get and it directly affects which accelerator tier you actually need.
Thinking in total cost of ownership, not sticker price
The headline hourly rate of an accelerator is one of the least useful numbers for making a decision. What matters is cost per successful inference at your real utilization. A premium GPU billed at a high hourly rate but kept busy at high utilization can be far cheaper per request than a "cheaper" chip that sits idle half the time waiting for traffic.
Three factors dominate true cost: utilization (idle accelerators burn money), throughput per chip (how many requests it serves under your latency target), and engineering and migration cost (porting to a new toolchain is real spend). Spiky or unpredictable traffic favors flexible, on-demand or autoscaled GPUs because you can scale to zero or down between peaks; steady, high-volume traffic favors committed capacity or specialized silicon you can keep saturated.
Model the full picture — reserved versus on-demand pricing, expected utilization, throughput on your model, and the one-time cost to adopt a new platform — before concluding that a different accelerator will actually save money. Many apparent savings disappear once low utilization and migration effort are counted.
A practical approach
Most teams should start on GPUs to get to production quickly with maximum flexibility, then optimize. Once a model and its traffic stabilize and volume grows, evaluate whether a TPU or custom-silicon path delivers meaningfully better cost-per-token or latency for that specific workload — and only migrate if the savings justify the engineering and lock-in.
Right-size relentlessly: many teams over-provision H100s for workloads an L40S-class card or a specialized inference chip would serve more cheaply. Benchmark on your own model and traffic rather than trusting vendor peak numbers, measuring real latency, throughput, and total cost (including utilization, not just hourly price).
The best accelerator is the one that meets your latency target at the lowest total cost for your actual workload.
Frequently Asked Questions
Are GPUs always the best choice for AI inference?
No, but they are the safest default. GPUs offer the broadest software support and flexibility, which is ideal for diverse or changing workloads. For one large, stable, high-volume model, TPUs or custom silicon can deliver better cost or latency — but GPUs minimize risk and engineering effort.
When do TPUs make more sense than GPUs?
TPUs make sense when you run large, stable workloads at high volume on Google Cloud and can work within their software stack (JAX/XLA, PyTorch/XLA). In those conditions they can offer strong throughput and competitive cost-per-token, and they scale into large pods for very large models.
What is custom silicon and who should use it?
Custom silicon means purpose-built inference chips like AWS Inferentia or Groq LPUs, optimized for specific tensor workloads. Teams with high, predictable inference volume — where price-performance or low latency is critical and the optimization effort amortizes — benefit most, accepting some ecosystem lock-in.
How do I compare accelerators fairly?
Benchmark on your own model and real traffic, not vendor peak FLOPs. Measure end-to-end latency, sustained throughput, and total cost including utilization, not just hourly rate. A cheaper chip that you cannot keep busy or that needs heavy tuning may cost more in practice.
Does memory matter more than compute for LLM inference?
Often, yes. Large-model inference is frequently memory-bandwidth and capacity bound, so high-memory accelerators (NVIDIA H200, AMD MI300X) or scaled TPU pods can matter more than raw compute. Always check whether your model fits and how memory bandwidth affects token throughput.
Should I switch hardware to save money?
Only after your workload stabilizes and you have benchmarked the alternative on real traffic. Migrating to TPUs or custom silicon adds engineering cost and lock-in, so it pays off mainly for high, steady volume where the per-inference savings clearly outweigh the switching cost.
Sources
- NVIDIA data center GPU and TensorRT-LLM documentation (H100, H200, L40S, L4).
- AMD Instinct MI300X and ROCm documentation.
- Google Cloud TPU documentation and PyTorch/XLA, JAX guides.
- AWS Inferentia/Trainium and AWS Neuron SDK documentation.
- Groq LPU inference documentation.
- Cerebras and SambaNova product documentation.
- VLLM, Hugging Face TGI, and NVIDIA Triton serving documentation.