 Pulse Reviews and Analysis
Pulse Reviews and Analysis
How do you build data pipelines for continuous model training?
 Curated by Kory White · Fractional CRO, CRO Syndicate
Curated by Kory White · Fractional CRO, CRO Syndicate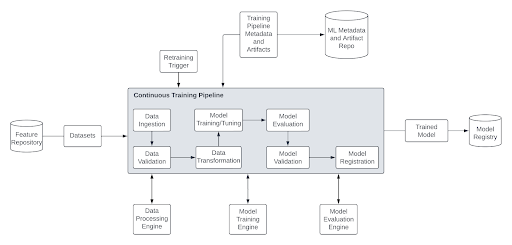
How do you build data pipelines for continuous model training?
Direct Answer
You build data pipelines for continuous model training by creating an automated, orchestrated flow that ingests fresh data, validates and transforms it, computes features, versions the resulting dataset, and triggers retraining and evaluation whenever new data or model drift warrants it — then promotes the new model only if it beats the current one.
The pipeline is event- or schedule-driven rather than run-by-hand: an orchestrator (Airflow, Dagster, Prefect, or Kubeflow Pipelines) coordinates stages; data validation (Great Expectations, TensorFlow Data Validation) guards quality; a feature store (Feast, Tecton, or a Databricks/SageMaker feature store) serves consistent features to training and serving; data and models are versioned (DVC, lakeFS, MLflow registry) for reproducibility; and monitoring detects drift to close the loop.
The core principle is that continuous training means continuous data: the pipeline must reliably and repeatedly turn new raw data into a validated, versioned training set and into a freshly evaluated, governed model.
Why continuous training needs a real pipeline
Models decay. The world that produced your training data keeps shifting — customer behavior changes, fraud patterns evolve, product catalogs turn over — and a static model silently gets worse as the live data distribution drifts away from what it learned. Continuous training counters this by retraining on fresh data on a schedule or in response to drift, so the model stays aligned with reality.
But retraining is only as good as the data feeding it. If the pipeline that prepares training data is manual, brittle, or inconsistent, every retrain risks introducing silent errors, schema mismatches, or training/serving skew. A robust, automated data pipeline is therefore the foundation of continuous training: it guarantees that each retrain runs on validated, consistent, versioned data, reproducibly.
The goal is to make a retrain a routine, trustworthy event rather than a risky manual project that a data scientist has to babysit.
Step 1: Ingest fresh data reliably
The pipeline starts by pulling new data from its sources — transactional databases, event streams, data warehouses, object storage, or third-party APIs. Two patterns coexist:
- Batch ingestion on a schedule (hourly, daily) for data that arrives in bulk, often via the warehouse or lake.
- Streaming ingestion (Kafka, Kinesis, Pub/Sub) for low-latency, event-driven data where freshness matters.
Ingestion should be idempotent and incremental — pulling only new or changed records — so reruns are safe and efficient. Landing raw data in a versioned lake or table format (Delta Lake, Iceberg) gives you a reproducible starting point for every downstream run. Capturing late-arriving and corrected records correctly matters too: design ingestion so a backfill or replay of historical data does not silently change features that earlier models were trained on.
Step 2: Validate data quality before it poisons the model
Garbage in, garbage out is brutal in continuous training because there is no human eyeballing each batch. Automated data validation is mandatory:
- Schema checks — types, required fields, and allowed ranges, so a renamed or dropped column halts the pipeline instead of silently corrupting features.
- Distribution checks — detect anomalies like a sudden spike in nulls, a shifted mean, or new categorical values.
- Tools — Great Expectations, TensorFlow Data Validation (TFDV), Pandera, or Soda encode these rules as tests that gate the pipeline.
A failed validation should stop the run and alert, not pass bad data into training. Treat these checks like unit tests for data: they should live in version control, run on every batch, and fail loudly. Over time, a library of expectations becomes documentation of what "good data" means for your model.

Reach Kory White, Fractional CRO: 📅 Book a Quick Call · 💼 Kory on LinkedIn · 🏢 CRO Syndicate
Step 3: Transform data and compute features consistently
Validated data is transformed into model-ready features. The critical governance concern here is training/serving skew — when features are computed one way for training and another way at inference, silently degrading production performance. The fix is a feature store:
- Feast (open-source), Tecton, and the Databricks and SageMaker feature stores let you define a feature once and serve it consistently to both training (offline) and serving (online).
- Feature stores also enable feature reuse across models and provide point-in-time correctness so you do not leak future data into training.
Transformations should be deterministic and versioned so a given input always yields the same features. Where transformations are heavy, push them into the warehouse or a Spark job rather than recomputing them ad hoc, and record the transformation code's version alongside the data so the feature logic itself is reproducible.
Step 4: Version the dataset and orchestrate the flow
Every training run must be reproducible, which means the exact training dataset is versioned and the workflow is orchestrated:
- Data versioning — DVC, lakeFS, or lakehouse time travel pins each retrain to the exact data that produced the model, linked to the model in a registry (MLflow, SageMaker).
- Orchestration — Apache Airflow, Dagster, Prefect, or Kubeflow Pipelines define the DAG of ingest → validate → transform → train → evaluate, with retries, scheduling, dependencies, and observability.
The orchestrator is what makes the pipeline "continuous": it runs on a schedule or fires on an event (new data landed, drift detected) without manual intervention. Good orchestration also gives you idempotent, retryable steps and clear lineage, so when a run fails at 3 a.m. It retries the failed stage rather than corrupting state or requiring a human to untangle a half-finished run.
Step 5: Trigger retraining, evaluate, and gate promotion
Continuous training does not mean blindly shipping every retrain. Define triggers and gates:
- Triggers — scheduled cadence, arrival of a data volume threshold, or — best — a drift/performance signal from monitoring that the live model is degrading.
- Evaluation — the newly trained model is scored on a held-out and recent dataset and compared against the current production model.
- Gate — only if the candidate beats the incumbent on the agreed metrics (and passes fairness/safety checks) is it registered and promoted; otherwise the current model stays. This prevents a bad retrain from replacing a good model.
Promotion itself should be a controlled rollout — canary or shadow first, then gradual — with the previous version retained for instant rollback if the new model misbehaves in production.
Step 6: Monitor and close the loop
Production monitoring is what feeds the triggers. Track input data drift, prediction distribution, and — where ground truth arrives — live accuracy. Tools like Evidently, Arize, WhyLabs, or Fiddler detect drift and degradation and can signal the orchestrator to kick off retraining.
This feedback loop — monitor → detect drift → retrain → evaluate → promote — is the essence of a continuous training system, and it is what distinguishes a living ML system from a one-off model that quietly rots in production.
Common pitfalls
- No data validation. Automated retraining without quality gates silently corrupts models; always validate before training.
- Training/serving skew. Computing features differently in training vs. Serving degrades production silently; a feature store prevents it.
- Unversioned data. Without dataset versioning you cannot reproduce or debug a model; pin every retrain to a data version.
- Promoting blindly. Always gate promotion on beating the current model; never auto-deploy an unevaluated retrain.
- Data leakage. Computing features without point-in-time correctness leaks future information; use point-in-time joins.
Frequently Asked Questions
What is the difference between continuous training and continuous integration? Continuous integration (CI) automates testing and building of code. Continuous training (CT) automates retraining models on fresh data. CT adds data-specific stages — ingestion, validation, feature computation, dataset versioning, evaluation, and promotion gating — on top of CI/CD, and is often triggered by data drift rather than code changes.
When should a model retrain — on a schedule or on drift? Both patterns are valid. Schedule-based retraining (e.g., nightly or weekly) is simple and predictable. Drift-triggered retraining is more efficient because it retrains only when monitoring detects the data distribution or model performance has shifted.
Many teams combine a baseline schedule with drift-based triggers.
Why do I need a feature store for continuous training? A feature store lets you define features once and serve them consistently to both training and serving, eliminating training/serving skew — a leading cause of silent production degradation. It also provides point-in-time correctness to prevent data leakage and enables feature reuse across models.
Feast, Tecton, and the Databricks/SageMaker feature stores are common choices.
How do I prevent a bad retrain from reaching production? Gate promotion: evaluate every candidate model against the current production model on a held-out and recent dataset, plus fairness and safety checks, and only promote if it wins. Register the approved model and deploy it through a controlled rollout with a rollback path to the previous version.
Which orchestration tool should I use? Apache Airflow is the most widely adopted general orchestrator; Dagster and Prefect offer more data-aware, modern developer experiences; Kubeflow Pipelines is Kubernetes-native and ML-focused. Choose based on your stack and whether you want a general workflow engine or an ML-specific one.
How do data and model versioning fit into the pipeline? Data versioning (DVC, lakeFS, lakehouse time travel) pins each retrain to its exact input data, and a model registry (MLflow, SageMaker) records each resulting model version linked to that data, its metrics, and its approval status.
Together they make every continuously trained model reproducible and auditable.
Sources
- Apache Airflow documentation — https://airflow.apache.org/docs/
- Dagster documentation — https://docs.dagster.io/
- Prefect documentation — https://docs.prefect.io/
- Kubeflow Pipelines documentation — https://www.kubeflow.org/docs/components/pipelines/
- Feast feature store documentation — https://docs.feast.dev/
- Great Expectations documentation — https://docs.greatexpectations.io/
- TensorFlow Data Validation — https://www.tensorflow.org/tfx/guide/tfdv
- Evidently AI documentation — https://docs.evidentlyai.com/
- DVC documentation — https://dvc.org/doc
- MLflow documentation — https://mlflow.org/docs/latest/